
本篇文章主要是面向对差分隐私零基础的朋友,我在介绍差分隐私相关的基础知识时尽可能地用简单的语言去讲解,因此准确性和严格性可能不太高,已经熟悉差分隐私的大佬们可以忽略该文章,也欢迎提出意见和建议!
一个例子
差分隐私是什么?我们为什么关注差分隐私?这里以一个例子来简单理解下:大家应该都知道QQ群中有群成员概况,可以显示群成员在全国各省市的分布数量、男女比例和具体人数,甚至还有单身数量的统计(这个现在的版本好像不会显示了)。假设张三在某一个QQ群中,平时就喜欢查看成员概况,然后某一天,你加入了这个群,张三看到群成员概况里面,男生或者女生人数突然增加了1,海淀区和90后人数增加了1人,还发现居然单身的人数又多了一个,然后一看群,发现你加进群了,于是对他来说,奇怪的知识又增加了,原来你是一只单身狗。但对于你来说,你也许并不想让你单身的信息被别人知道,但因为上面发生的情况,你的信息就无意识的被暴露了。那为了避免这种事情的发生,有什么办法呢?差分隐私就应运而生了。它就是用来解决这类问题,让攻击者不会因为新样本的出现而推测到新的信息。
差分隐私的定义
对于随机函数$M$,$P_m$是$M$的所有可能的输出结果的集合,$Pr[\cdot]$表示概率,对于任意两个只相差一项纪录的数据集,即相邻数据集$D$和$D’$,$P_m$的任意子集$S_m$,算法$M$满足:
那么就说明该函数提供$\epsilon-$差分隐私保护。
我觉得应该不止我一个人第一次看到这个数学定义会感觉有点懵吧,用人类能听懂的话和这个图来理解,就是两个相差一条记录的数据集,随机函数看作查询函数,对这两个数据集进行查询,然后我们把查询结果映射到概率分布上,这两条曲线就是查询结果映射后的概率分布曲线。如果两次结果的概率分布非常接近,那么就说它满足$\epsilon-$差分隐私保护。这个接近的程度是由这个$\epsilon$决定的,我们称之为隐私预算。由定义的不等式可以看出,隐私预算越小,分布越接近,保护程度越大,但反过来想,要使分布越接近,那么势必会引入较大噪声,数据精度会受到更大的影响。
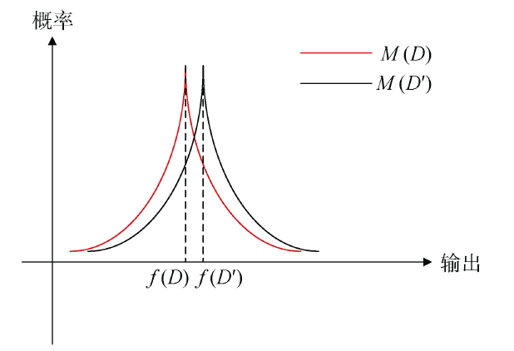
就刚刚张三那个例子而言,你加入群前,张三看到这个单身人数是56个,你加进去之后,张三看到的单身人数还可能是56个,这样就保护了你单身这个个人隐私。定义里面的数学不等式,是以两个$D$和$D’$分布尽可能的接近为目的来计算得到的,利用了信息论中的KL散度和Max散度推导而来。感兴趣的同学可以自行深入了解。
那么关于这个定义,还有最后一个问题就是,为什么$\epsilon$被称为隐私预算呢?既然被称为预算,那么就说明差分隐私保护是会被消耗的,我们来简单的理解一下:我们知道查询结果是一个概率分布了,那作为攻击者来说,我可以不断地进行同一个查询,如果查询次数足够多的话,攻击者可以猜到结果的概率分布,进而推测出准确值,那么说明丧失了隐私保护能力了。那么每一次查询都可以看作消耗了$\epsilon$的隐私保护,我们固定一个总的能被允许的消耗,而$\epsilon$越小,那么表示会有更多次查询才会使隐私保护能力丧失。这里也可以看出差分隐私保护也许和我们日常理解的隐私保护不同,它是有限制的,会被消耗的,不是一旦使用了差分隐私保护机制就能够永久保护隐私的。
从定义就可以看出,差分隐私能够防止攻击者拥有大量背景知识进而推测出隐私信息,同时其建立在严格的数学定义上,提供了可量化评估的方法。
性质
差分隐私还有一些有趣的性质:串行组合、并行组合、变换不变、中凸;
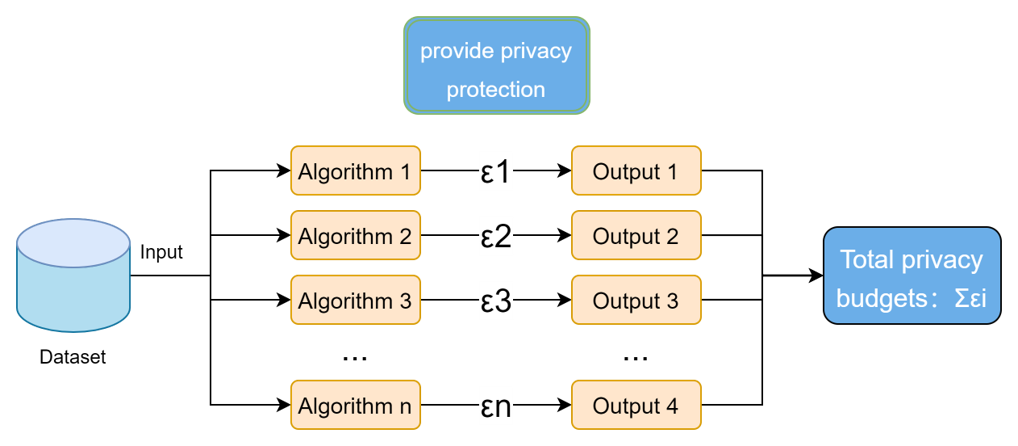
其中串行组合的意思就是如果k个差分隐私保护算法同时作用于同一个数据集,那么最终的隐私预算就等价于这k个算法的预算和;这也很好理解,假设第一次加噪声处理后有$\epsilon$的预算了,第二次的时候又进行了一次差分隐私保护处理,又添加了噪声,那么噪声就更大了,那么隐私预算也应该相应的增加。
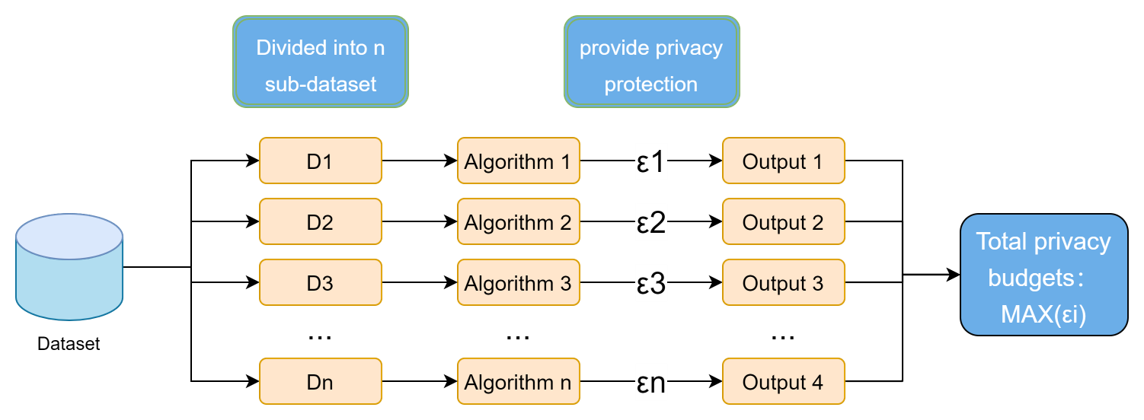
并行组合就是多个算法分别作用在同一个数据集上的多个子集上,最终隐私预算等价于这些算法中隐私预算最大的一个。
变换不变:对于任意算法A1满足ε-差分隐私,对于任意算法A2,有A(·)=A2(A1(·))满足ε-差分隐私。
中凸:两个算法都满足ε-差分隐私,这两个算法分别以p和1-p的概率使用,构成一个机制,则该机制满足ε-差分隐私。
常见机制
Laplace机制(针对数值型数据)和指数机制(针对离散性数据),其核心思想就是对查询结果添加适量扰动、噪声,来满足差分隐私保护。其中,对加入噪声进行的度量由敏感度来决定,敏感度指数据集中删除任意一条记录对查询结果产生的最大影响:
敏感度又分为:
全局敏感度:核心是对于查询函数的作用域上,任意相邻数据集删除任意一条记录对查询结果产生的最大影响。只与查询函数本身有关。
局部敏感度:对于给定的相邻数据集,删除任意一条记录对查询结果产生的最大影响。与查询函数本身和选定的数据集有关
敏感度越大,所需要加入的噪声也就越大。
Laplace机制
Laplace机制如下公式所示,其中,f(D)表示的是查询函数, 表示的是满足Laplace分布的随机噪声, M(D)表示的是最后的返回结果。
特点:适合数值型数据,ε越小,添加的噪声越大。
指数机制
以
的概率输出结果$R_i$。其中$q$表示一个打分函数,$D$表示数据集,$R_i$表示一个输出结果,这个函数的意思就是对$D$的输出结果打分。得分高的输出概率高,得分低的输出概率低。