
摘要
LDP优势:数据收集者不用访问敏感数据而收集到精确的统计估计。
论文主要工作:
- 设计了一个基线方法PrivKV;
- PrivKVM和PrivKVM+两个迭代方案去提高估计精度;
- 一个优化策略来减少网络延迟和提高精度;
- 验证以上方案的正确性和效率
Introduction
论文工作内容概述:
- Local perturbation protocol (LPP) 扰动key-value对;
- 三个基于LPP的方案:PrivKV,PrivKVM,PrivKVM+;
- 一个优化策略让数据收集者执行虚拟PrivKV迭代,减少网络延迟和提高数据精度
Related Work
LDP可用于:
- 分类数据上的频率估计;
- 用频率估计作为保护数据隐私的原语;
- 数值型数据的均值估计;
Preliminaries and Problem Definition
A. 本地化差分隐私(LDP)
LDP的基本流程:数据拥有者在本地使用随机机制扰动数据$\rightarrow$传递这个”消毒“版本数据给不受信任的数据收集者中。
定义1 $\epsilon-LDP$:$D$表示整个数据集,一个随机化函数$\mathcal{M}$满足$\epsilon-LDP$,当且仅当任意两个输入数据元组$t,t’\in D$和任意输出$t^*$,以下不等式始终成立。
与中心化差分隐私定义在两个相邻数据集不同,$\epsilon-LDP$是定义在一个数据集的两个数据元组上,可以直观的理解为通过观察输出$t^*$,数据收集者不能通过高置信度(由$\epsilon$控制)推断出输入元组是$t$或是$t’$
满足顺序合成性(Sequential Composition)
第五节中的迭代解决方案,利用了顺序合成性,给定一个隐私预算$\epsilon$,可以将其分为多个部分,每一个预算都可以被用于一个随机算法来从源数据中收集可用信息。
B. 随机响应(RR)
随机回答一些敏感的布尔问题来实现看似可信的否认能力。一般回答真实答案的概率为$p$,回答对立答案的概率为$1-p$。
为使RR满足$\epsilon-LDP$,设置$p$为$p=\frac{e^{\epsilon}}{1+e^{\epsilon}}$,但“真”的概率(表示为$f$)是直接从所有被扰动后存在偏差的回答中获取的,所以数据收集者需要校准并报告$f’$:
C. 问题定义
LDP背景下key-value数据上的分布式数据聚合问题
论文关注与两个基本估计:
- 频率估计:密钥$k$的频率$f_k$定义为拥有密钥为$k$的$KV$对的用户部分占总用户的比例。
- 均值估计:键$k$的均值$m_k$定义为键为$k$的$KV$对中所有值的均值。
PRIVKV: A BASELINE APPROACH
基线方法PrivKV通过对key和value添加扰动来保护key-value数据,同时几乎保留真实的频率和均值。
A. 有缺陷的键扰动协议
首先转化$KV$对集合,将键转化为$\{0,1\}$上的整数值,1表示存在KV对,0表示不存在KV对:
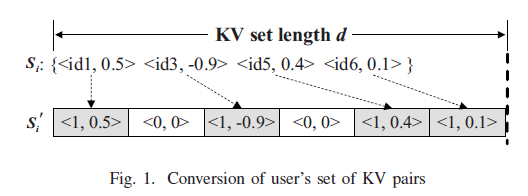
对键$k$直接使用RR,对值的更改基于对键的扰动,有以下四种情况:
$1\rightarrow1$:保留原值$\langle1,v\rangle\rightarrow\langle1,v\rangle$
$1\rightarrow0$:值置为0$\langle1,v\rangle\rightarrow\langle0,0\rangle$
$0\rightarrow0$:KV对不存在,也就不存在改变$\langle0,0\rangle\rightarrow\langle0,0\rangle$
$0\rightarrow1$:新形成的KV对,值随机从$\{-1,1\}$之间取
其缺陷在于第四种情况:首先,随着数据者接收到更多的真值,她能够以高置信度区分真值(情况1)和指定的值(情况4),特别是当真值的分布明显与$[-1,1]$上的均匀分布偏离时。 其次,[−1, 1] 的均匀分布导致均值为 0,这会影响该键的均值估计。
B. 本地扰动协议:补救措施
一种补救措施:无论是真实值还是指定值,任何值都添加干扰。
Harmony算法:离散、扰动、校准

原始的值扰动算法:基于Harmony,将校准步骤移至数据收集者方,设置数据收集者能够精确地对键计数并求和值来计算均值,在校准后添加条件校正(eg:假设总共有对-1和1的计数,若),去除由Harmony引起的异常值。

组合键扰动协议和原始值扰动算法得到本地扰动协议(LPP):

LPP满足$(\epsilon_1+\epsilon_2)-LDP$
C. PrivKV:把事情结合起来
PrivKV对频率和均值的完整方案,包含用户端的扰动和收集者端的校准。

论文将任何大于N或小于0的计数视为异常值,并修正他们分别为N和0。
1 | 对于频率和均值为什么几乎一致? |
PrivKVM: AN ITERATIVE SOLUTION
PrivKV存在的问题:PrivKV以不当分配新值来保证LDP
PrivKVM和PrivKVM+的做法:多次迭代PrivKV让分配的新值所在的分布基本与真实值相同。
A. 一个迭代模型
前一个$v^*$的离散化估计均值作为下一个迭代的分配值。迭代模型如图:
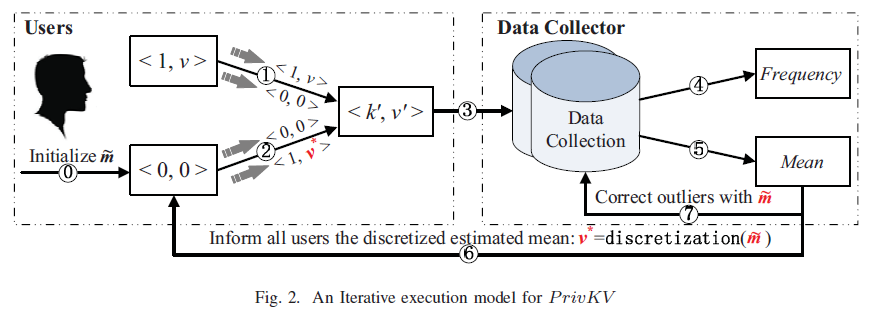
为防止步骤六中$\tilde{m}$被泄露给用户,数据收集者不会直接将其回传给用户,而是通过当前迭代返回一个新的且独立的样例值$v^*$,该值是$\tilde{m}$的离散化值,它分别以$\frac{1+\tilde{m}}{2}$和$\frac{1-\tilde{m}}{2}$的概率被设置为1或-1。由于这两种概率仅为数据收集者所知,任何用户都无法推断$\tilde{m}$,除非大量用户串通并共享其接收到的1和-1。在这种极端情况下,保护$\tilde{m}$不再是必要的,因为这些用户可以自己推导出来。
数学上可证明:算法的求得的均值$\tilde{m}_k^*$是真实的$m_k$的近似解。核心思想就是如果数据收集者返回的估计均值,基于这个值对所有原始数据的估计就可以估计出key的对应的均值,并且估计是无偏估计。
对于迭代模型中的步骤5、7,可以设计基于先验知识的异常值校正方案:
数据收集者记录上一次迭代的估计平均值。在随后的迭代中,所有出现的异常值都将被这些记录的平均值所取代。这种校正方案也有助于提高迭代模型的精度。
B. PrivKVM
该算法如下所示,需要注意的是隐私预算$\epsilon$通过隐私预算分配策略(PBA)被分为$\{\epsilon_{11},…,\epsilon_{1c},\epsilon_{21},…\epsilon_{2c}\}$,PBA有线性分配、均匀分配、指数分配、自适用性分配以及混合分配等,通过分析敏感度等方面,分配合适的隐私预算。

其中在本地差分隐私中$v^*$用于原本不存在的键被扰动成键为1时,其值的取值。
论文的PBA类似于均匀分配:首先平均分配隐私预算$\epsilon$用于keys和values,比如$\epsilon_1=\epsilon_2=\frac{\epsilon}{2}$。在迭代中,只需要第一次的key作为输出,因此$\epsilon_{11}=\epsilon_1$,且$\epsilon_{12},…,\epsilon_{1c}=0$;对于均值估计,将$\epsilon_2$平均分配给每一次迭代。
1 | 对于键,是否需要这么大的隐私预算?该方案中的PBA是否合理?(论文是否有阐述为什么采取该PBA) |
对于多维数据,PrivKVM拓展直观。对于键,直接展开到键域上成为一维;对于值,对每一维度的值分别单独扰动。不会损失键和每一维值的相关性。
PrivKVM还可以用于中位数和百分比统计。中位数利用频率表,分成两个面积相等的区域,中间的即为中位数。为了提高估计精度并减少对均匀假设的依赖,论文通过在频率直方图中使用多个 bin 来进一步推广这个想法。
PrivKVM适用于:归档数据集收集、历史数据。真实时间数据不太适合。
多次迭代会增加数据收集的响应时间(影响数据收集效率)。只要键或值分布没有改变,PrivKVM 仍然可以处理迭代之间的键值数据变化。
C. 隐私和准确性分析
PrivKVM满足$\epsilon-LDP$(根据顺序合成性质)
PrivKVM的真实均值与估计均值的期望值之差收敛为零。
PrivKVM在最坏情况下,真实均值与估计均值的差值是有界
D. PrivKVM+:一个自适应变种
PrivKVM需要迭代$c$次,但这个次数很难确定。理论情况下,$c$无穷大时,精确度最好,但通信和执行时间会巨大。因此提出PrivKVM+取根据消耗(通信、执行时间等)自适应的决定$c$的值。
论文定义了一个开销函数$F(r)=F_1(r)+F_2(r)$,其中$F_1(r)$是准确率开销、$F_2(r)$是通信开销(由于执行时间由通信带宽决定,论文将执行时间成本合并到通信成本中)。
$F_1(r)$通过所有键的均值的绝对误差的平均值计算:
因为每次通信的开销是一个常数值,所以有:
当迭代次数$r$增大,$F_1(r)$减少并且相对越来越不重要,而$F_2(r)$以恒定比例$A_0$增长。因此,当$F_1(r)$的减少不能再补偿$A_0$的增加时,$F(r)$达到全局最小值。当第一个$F(r)-F(r-1)=A_0-\frac{1}d\sum_{k\in\mathcal{K}}|m_k^{(r)}-m_k^{(r-1)}|\geq0$时,也就是说第一次出现第$r$轮迭代产生的开销大于第$r-1$时,就选取迭代次数为$r$,此时的总体开销最小。(论文未严格证明,只是上式很容易被算法实现)
PrivKVM+算法在隐私预算分配时,使用PBAt策略,该策略使用了“指数衰减”策略($t=a(1-b)^x$)动态地将剩余的隐私预算的$\frac{1}t$分配给当前迭代(这样一开始的t比较大,然后逐渐变小,也就是说一开始分配的隐私预算小,收敛慢,到后面分配的隐私预算越来越大,估计逐渐收敛,这样会比较精确。但文章中没有说明初始t值的选取,该值的估计个人认为又是一个待研究的问题)。t 可以是任何大于1的值。t越小,分配给当前迭代的隐私预算就越大,估计收敛得更快。但如果t太接近1,则收敛可能会过早,因为大多数隐私预算都浪费在早期迭代中,其中估计的均值对于下一次迭代来说就十分不准确了。

第2步与LPP算法不太一样,这里是直接设置一个初始$\tilde{m}=1$,论文没有说明具体这样做的理由。
VIRTUAL ITERATIONS: AN OPTIMIZATION ON LATENCY AND ACCURACY
优化策略的简单理解:选择一些迭代进行真的在用户方进行计算,其余的迭代过程全在数据收集者处完成。
优点:原本的算法需要每次计算出均值然后让用户再来根据数据收集者计算的均值回馈,然后迭代计算。这样用户需要频繁计算和通信。优化策略就只要从用户那里收集一次数据,后面的c−1轮迭代,可以自己完成,这里称为虚拟迭代(Virtual Iterations)。这样能有效地降低用户和收集器之间的网络传输开销,从而提高了延迟;其次,由于虚拟迭代不会花费任何隐私预算,因此可以为真实迭代分配更多的隐私预算,从而提高估计精度。

算法中的重要的点在于计算$\theta$和预测第$c$次迭代的均值$m_k^{(c)}$。
证明过程利用了真实均值与估计均值的期望值之差收敛为零这个性质。
1 | 证明利用的性质是基于完整的迭代过程去逆推每一次迭代的均值的期望,以最优的期望取预测每一次的均值,所以如果迭代次数很多时,在虚拟迭代会放大真实迭代的效果(相当于迭代了更多次) |
论文中说明虚拟迭代的精度增益很大程度上取决于第一次迭代的精度。 然而,如果后者只被给予很小的隐私预算,例如 = 0.05,则在第一次迭代中引入的压倒性噪声可能会通过虚拟迭代进一步累积。(由此也可以看出如果要使用优化策略,无论是PrivKVM还是PrivKVM+,都需要考虑隐私分配策略是否合理)正如将在性能评估中显示的那样,除非隐私预算很小,否则这种优化策略可以很好地工作。
EXPERIMENTAL EVALUATION
在实验评估中,分别对key的频率估计和value的均值估计进行了对比实验:
- 对于keys:与RAPPOR,k-RR,和SHist进行比较(使用与论文方案相同的采样技术);
- 对于values:将PrivKVM-Harmony和PrivKVM-MeanEst与PrivKVM进行对比
因为进行对比的方案有的只能处理分类(key)或数值型(value),为了公平,实验尽可能的调节这些方案使其能够适应key-value背景下的数据。
数据集采取了6个数据集:
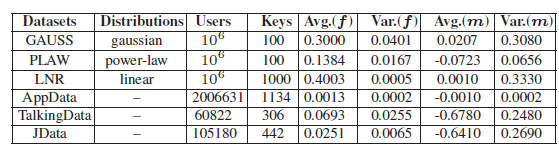
前三个是合成数据集,分别满足高斯、幂律、线性分布,后三个是采样的实际的公共数据资源。
论文采用了相对误差(RE)和均方误差(MSE)取对数进行评估的计数。
A. 总体结果
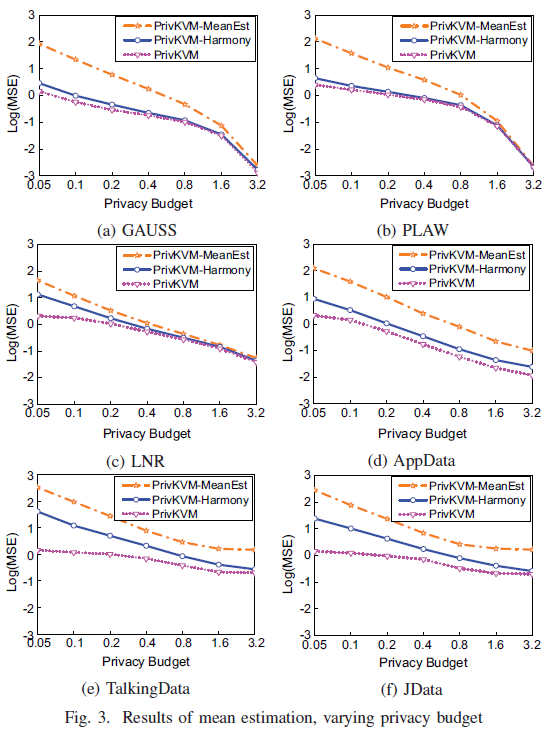
从总体来看,PrivKVM在均值估计上比其他两个方案更加精确,特别是在隐私预算较小和真实数据集上。隐私预算较小时较好是因为小的隐私预算会导致高的扰动,因此导致更多的异常值,而PrivKVM有对异常值做校正,所以会比较有优势;对于真实数据,是因为异常值在真实数据集(KV对非常稀疏)中更容易出现。论文提到图中(d)(e)(f)的均方误差的绝对值要普遍高于前三个,是因为样本数据量要少于前者。
对于频率估计,在不同隐私预算下,PrivKVM在PLAW数据集上的相对误差都优于另三种,在Appdata数据集上,因为采样数据集是非常稀疏的,因此键是非常嘈杂且无意义,论文只绘制了前100个键的的频率估计下的相对误差,即使在此情况下,PrivKVM依然是最优。
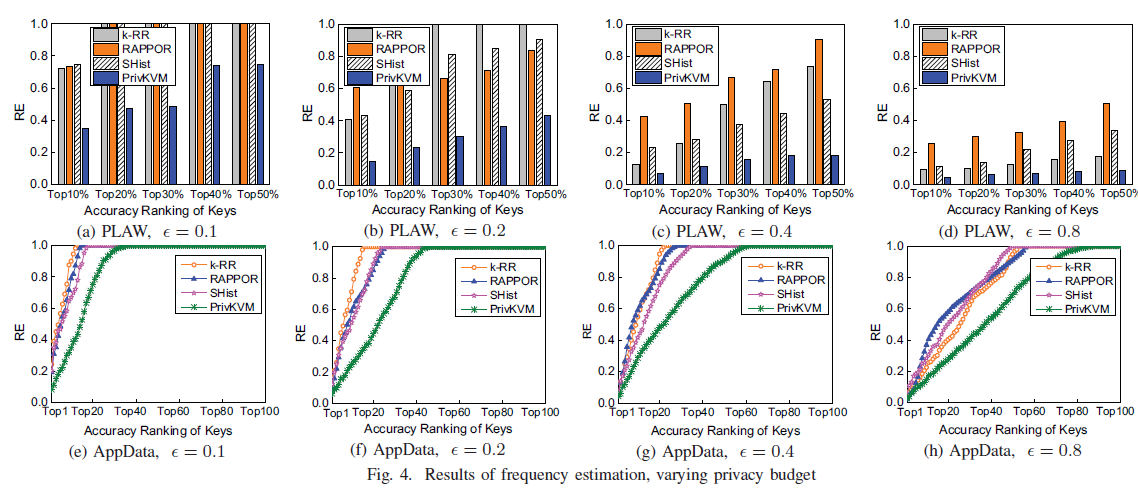
比较端到端宽带开销,论文展示了在用户和数据收集者间传输Appdata的比特位数(不太明白为什么会是图示大小,PrivKVM是PrivKV的9倍,因为第一次是从用户打给数据收集器端。):
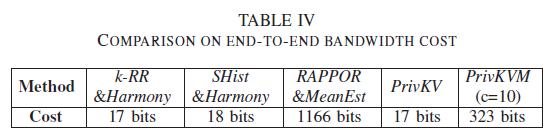
B. 可拓展性
这里可拓展性是指用户数量或键空间尺寸对数据的频率和均值估计的影响程度。这里其实意思就是,虽然大家都知道对于同一个方法数据越多越准确,但是同样的数据下,你的方法比别人准确就是你厉害了。下图展示了不同用户数量下的误差,可以看出论文的方案均优于对比方案
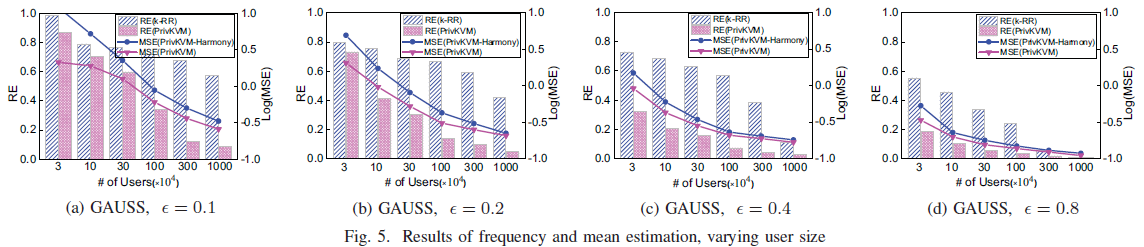
对于键空间尺寸而言,从下图中也可以看出其对频率和均值的估计的影响都优于其他算法,这里随着键数量增加误差增大的原因是,用户数固定,如果其键空间尺寸增多,那么对于每一类键,它的数量是减少的,所以导致了误差增大。

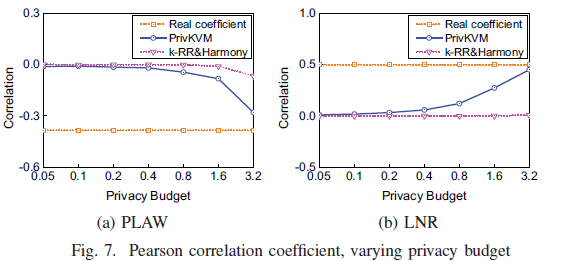
C. key-value的相关性
使用了Pearson相关系数(?)作为度量并在PLAW和LNR上进行测试。从下图可以看出,隐私预算较大的情况下,PrivKVM处理后的KV对的相关性接近原KV对,而k-RR处理键结合Harmony处理值的这一方案,键值对的相关性基本被消除了。
为了进一步说明不同频率的键之间键值相关性的保留情况,在高斯分布的数据集上绘制了键和均值的三维图,如下图所示,可以清楚的看出PrivKVM处理后保留了一定的相关性。
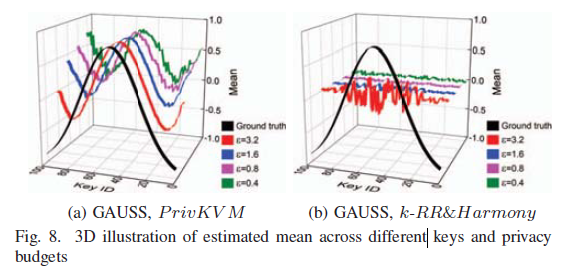
D. 迭代的影响
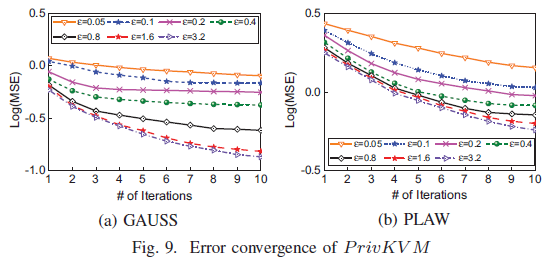
论文评估了PrivKVM中的迭代对均值估计精度的影响。 下图显示了在GAUSS和PLAW上的结果。 对于每个隐私预算,论文尝试10次PrivKVM运行,迭代次数从1到10不等。可以看出,在合成数据集中,$Log(MSE)$随着迭代次数的增加而减小并收敛到某个值。 这个值完全是由于值扰动引起的,因为论文已经证明预期和实际均值之间的绝对误差会收敛到零。
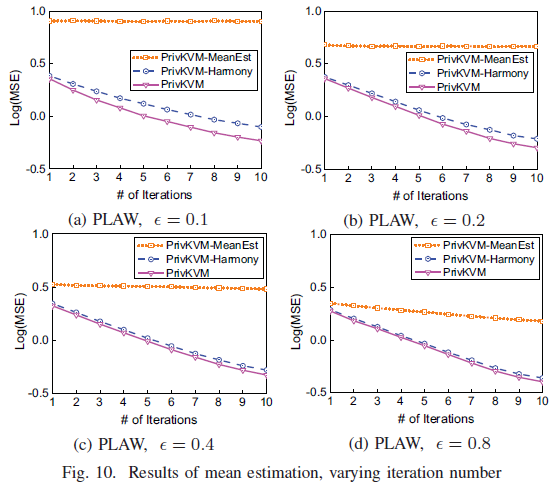
然后还比较了其他方案进行迭代后的均方误差,PrivKVM-Harmony的均方误差其实与PrivKVM差不多,PrivKVM-MeanEst的均方误差基本不变,因为这个方案只适用于域仅有几个键组成的情况。同样的,在隐私预算较小的情况下优势更明显。
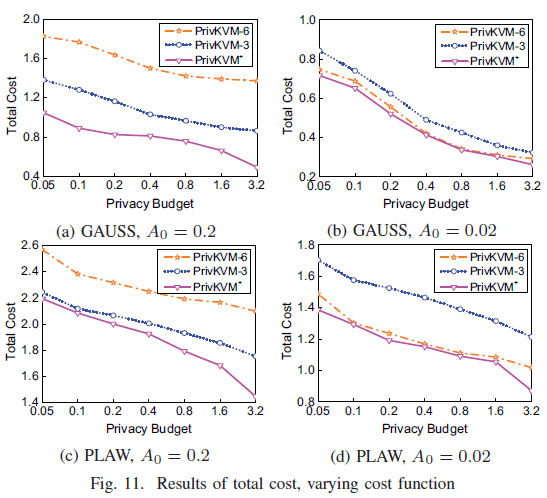
E. 开销函数的影响
从图中可以看出当通信开销的系数为$A_0=0.2$时,迭代6次比迭代3次开销大,系数比较小的时候($A_0=0.02$)第3次的开销大于第6次,由于PrivKVM+是寻找合适的迭代次数来实现最低成本,由论文的论述,可以知道前者可能迭代2,3次,后者则可能是4 5 6次迭代。
F. 虚拟迭代优化的影响
实验对比了使用虚拟迭代和不使用虚拟迭代策略的情况, 对于前者,我们将要执行的迭代次数$c$设置为 6,这意味着在涉及用户的第一次真正迭代之后将执行 5 次虚拟迭代。 不使用虚拟迭代的迭代次数设置为 6。下图显示了在 GAUSS 和 PLAW 上的结果。
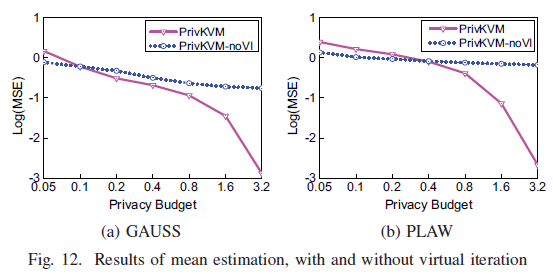
可以看出观察到,当隐私预算非常小时,PrivKVM 返回的结果非常不准确。 这是因为虚拟迭代的效果在很大程度上取决于第一次真实迭代的准确性,当预算太小时,这是很糟糕的。 当预算增加时,PrivKVM 的准确性提高得很快,就超过了 PrivKVM-noV I。表明虚拟迭代可以放大真实迭代的效果,无论它是好是坏。
CONCLUSION
论文设计了一个基于LDP的key-value数据的频率和均值估计的去中心化的隐私保护机制,其提出了三个基于本地扰动协议的方案PrivKV、PrivKVM和PrivKVM+。还提出了虚拟迭代优化策略。并对以上进行了理论和实验分析。
未来的研究:论文计划研究更多关于键值数据的聚合统计,例如最大值和最小值估计。 我们还计划探索 LDP 用于隐私保护挖掘任务(例如,查找梯度下降或 k 均值聚类),并将这项工作扩展到具有关系依赖关系的查询(例如,自然连接)和未知的关键空间。
可能存在的问题
首先该算法的离散化处理,将value二元化,这样对于数据集的统计操作的局限性就很大,就基本只能做做均值、频率、中位数,而做不了有梯度的统计或者是统计最大值或者最小值之类的。
同样,因为它是离散到二元的,那么如果数据量不够大误差是会很大的,论文也没有方案讨论适用于什么数量级的情况。
然后就是PrivKVM+自适应确定迭代次数,文章中没有说明初始t值应该如何选取,才能使该方案有较好的效果,该值的估计个人认为又是一个待研究的问题。
在虚拟迭代中,初始化均值取值算法不同于LPP,他是直接取1,论文同样没有阐述为什么这样做,而且虚拟迭代的精度很大程度取决于第一次迭代均值的精度,这一点又与隐私预算分配相关,如果给太多,虽然第一次精度有一定保证,但迭代收敛过快,还是可能造成精度损失大;若给太少,迭代收敛慢,但第一次精度不足,同样会导致精度问题。论文没有给出具体应该如何确定第一次迭代的精度的检测方案,也没有给出该如何得到较优的第一次迭代的均值。
PrivKVM算法的真实均值和估计均值的最大差异部分没有太明白,还需要看参考文献中的证明。